Estimating fatality risk from individual level data
Source:vignettes/estimate_from_individual_data.Rmd
estimate_from_individual_data.RmdThe main examples showcased in the vignettes of the cfr package use incidence data (i.e. counts of cases and deaths by day). However, in some instances individual-level data (i.e. where each row provides information about a single case) will be available, which opens up additional analysis options, but also some potential biases.
What we have
- A linelist of case onset timings, as well as either individual outcome (i.e. death, recovery) if it has occurred by this point and been recorded, or total deaths.
- Data on the distribution of delay from onset-to-death, describing the probability an individual will die days after they were initially infected.
# load {cfr}
library(cfr)
# packages to wrangle and plot data
library(dplyr)
library(magrittr)
library(ggplot2)
library(tidyr)
library(incidence2)Estimation based on cases with known outcomes
If we have individual-level data on case onset timings and outcomes, where available, it is common to filter the data to focus on cases only with known outcomes. This means the case fatality risk can then be calculated from this filtered dataset containing only known outcomes:
One limitation of this method is that it implicitly assumes the delay from onset-to-death and onset-to-recovery are the same (see below for the mathematical proof). If these delays are noticeably different, the above calculation will produce a biased estimate of the CFR. For example, if onset-to-recovery is much longer than onset-to-death, at a given time point mid-outbreak, the denominator above will be an underestimate of the true number of cases that would eventually recover who have similar onset timings to those that would eventually die. Hence this calculation would inflate the CFR estimate. After the mathematical explanation below, the next section will discuss estimation methods based on the expected number of known death outcomes using functionality in cfr.
Mathematical explanation for bias
If we have a linelist with known outcomes and onset-death delay follows the same distribution as onset-recovery, and CFR = , then at the current time,
and
where is number of new symptomatic infections on day and is the probability of outcome days after symptom onset.
Hence
However, if delay to death is different to delay to recovery , we have:
And hence this will not simplify to provide an unbiased estimate of , as if would if .
Estimation based on expected number of known death outcomes
If the delay from onset-to-death and onset-to-recovery are different, one option is to use survival analysis methods to estimate relative hazards (i.e. fatality risk) over time.
However, if we are only interested in an overall estimate of CFR, a simpler alternative is to first calculate the number of cases in the linelist that we would expect to have a known outcome by this point if the outcome were fatal:
where is the CFR.
We can then rearrange the above to calculate the CFR:
This is the calculation performed by cfr_static(), and
hence this function can give us a better estimate of CFR when delays to
death and recovery are not the same.
Simulated comparison of above methods
To compare these methods, i.e. filtering out cases without known
outcomes vs using the cfr_static function, we first
simulate 1000 case onset timings and outcomes (i.e. deaths and
recoveries)
# Simulate data
nn <- 1e3 # Number of cases to simulate
pp <- 0.1 # Assumed CFR
set.seed(10) # Set seed for reproducibility
# Generate random case onset timings in Jan & Feb 2024
case_onsets <- as.Date("2024-01-01") + sample.int(60, nn, replace = TRUE)
# Define current date of data availability (i.e. max follow up)
max_obs <- as.Date("2024-01-20")
# Sample delays from onset to outcome
# 1. Deaths: assume mean delay = 5 days, sd = 5 days
log_param <- c(meanlog = 1.262864, sdlog = 0.8325546)
delay_death <- function(x) {
dlnorm(x,
meanlog = log_param[["meanlog"]],
sdlog = log_param[["sdlog"]]
)
}
outcome_death <- round(rlnorm(round(nn * pp),
meanlog = log_param[["meanlog"]],
sdlog = log_param[["sdlog"]]
))
# 2. Recoveries: assume mean delay = 15 days, sd = 5 days
log_param <- c(meanlog = 2.65537, sdlog = 0.3245928)
outcome_recovery <- round(rlnorm(round(nn * (1 - pp)),
meanlog = log_param[["meanlog"]],
sdlog = log_param[["sdlog"]]
))
# Create vector of outcome dates
all_outcomes <- case_onsets + c(outcome_death, outcome_recovery)
# Create vector of outcome types
type_outcome <- c(rep("D", length(outcome_death)),
rep("R", length(outcome_recovery)))
# Create vector of known outcomes as of max_obs
known_outcomes <- type_outcome
known_outcomes[(all_outcomes > max_obs)] <- ""
# Create a data frame with onset and outcome dates, and outcome type
data <- data.frame(
id = 1:nn,
case_onsets = case_onsets,
outcome_dates = all_outcomes,
outcome_type = type_outcome,
known_outcome = known_outcomes
)
# Filter out unknown outcomes (after the max_obs date)
data <- data %>% filter(nzchar(known_outcome))
# Arrange data by onset date
data <- data %>%
arrange(case_onsets) %>%
mutate(id_ordered = row_number()) # Assign a new 'id_ordered'
# Prepare data for plotting (onset and outcome events in same column)
plot_data <- data %>%
tidyr::pivot_longer(
cols = c(case_onsets, outcome_dates),
names_to = "event_type",
values_to = "date"
) %>%
mutate(
event_label = ifelse(event_type == "case_onsets", "Onset", "Outcome")
)
# Create plot with lines linking onset and outcome
ggplot() +
geom_segment(
data = data, aes(x = case_onsets,
xend = outcome_dates,
y = id_ordered,
yend = id_ordered),
color = ifelse(data$outcome_type == "D", "red", "green"),
size = 0.5
) +
geom_point(data = plot_data, aes(x = date,
y = id_ordered,
color = outcome_type,
shape = event_label),
size = 2) +
geom_vline(xintercept = as.numeric(max_obs),
linetype = "dashed",
color = "black",
size = 0.5) +
scale_color_manual(values = c(D = "darkred", R = "darkgreen")) +
scale_shape_manual(values = c(Onset = 16, Outcome = 17)) +
labs(
x = "Date",
y = "Individual (Ordered by onset date)",
color = "Outcome type",
shape = "Event type"
) +
theme_minimal()
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
#> ℹ Please use `linewidth` instead.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
#> generated.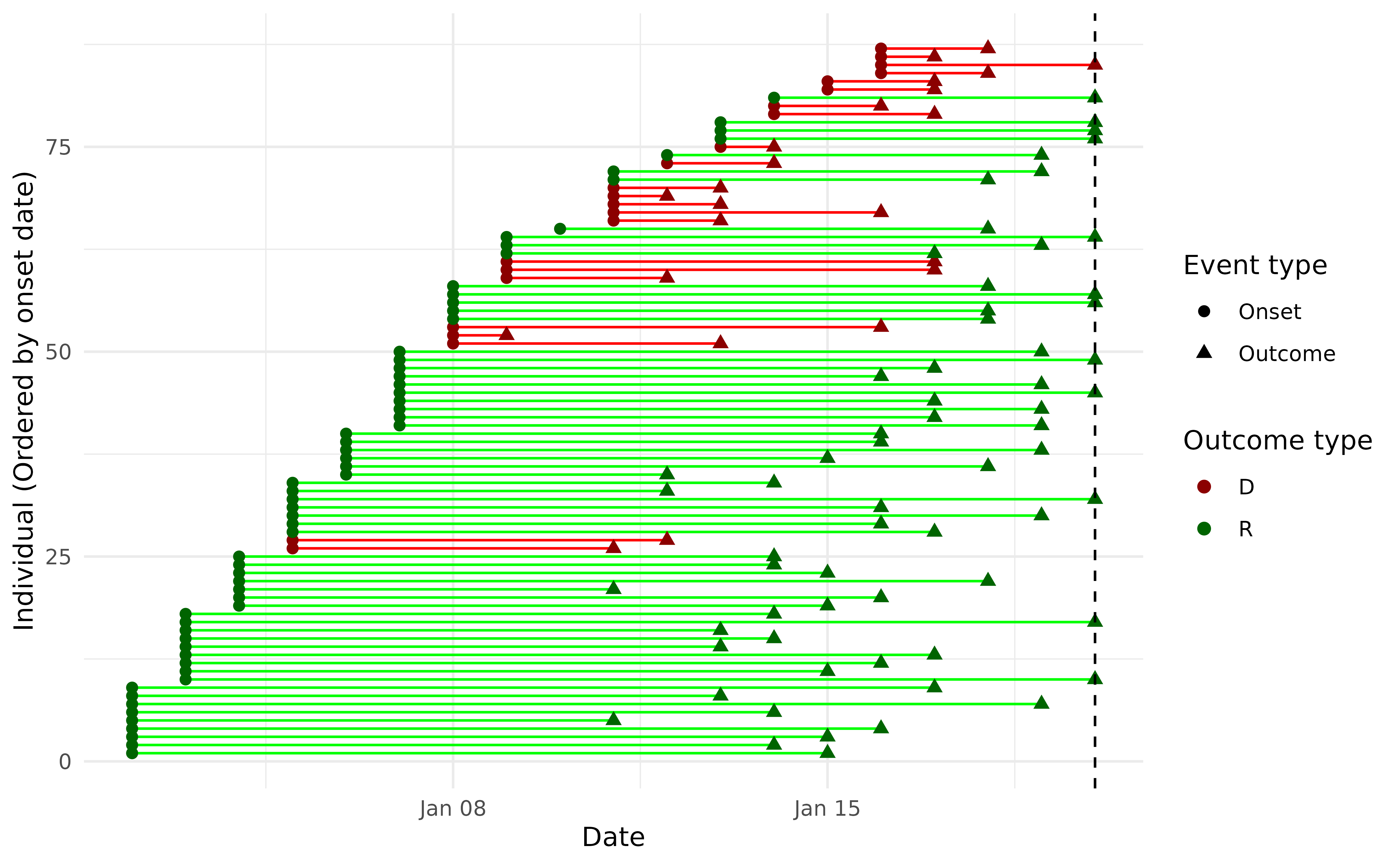
Individual level timings of onsets and outcomes, for individuals with a known outcome as of 20th Jan 2024.
First, we calculate CFR by filtering to focus only on cases with known outcomes:
# Filter on known outcomes
total_deaths <- sum(known_outcomes == "D")
total_outcomes <- (total_deaths + sum(known_outcomes == "R"))
# Calculate CFR with 95% CI
cfr_filter <- binom.test(total_deaths, total_outcomes)
cfr_estimate <- (signif(as.numeric(c(cfr_filter$estimate,
cfr_filter$conf.int)), 3))
cfr_estimate
#> [1] 0.264 0.176 0.370Next, we calculate CFR based on expected fatal outcomes known to
date, using cfr_static()
# Get times of death for fatal outcomes
death_times <- (case_onsets)[type_outcome == "D"] + outcome_death
# Create a single data.frame with event types
events <- data.frame(
dates = c(case_onsets, death_times),
event = c(rep("cases", length(case_onsets)),
rep("deaths", length(death_times)))
)
# Use incidence2 to calculate counts of cases and deaths by day
counts <- incidence2::incidence(events,
date_index = "dates",
groups = "event",
complete_dates = TRUE)
# Pivot incidence object to get data.frame with counts for cases and deaths
df <- counts %>%
tidyr::pivot_wider(names_from = event,
values_from = count,
values_fill = 0) %>%
dplyr::rename(date = date_index)
cfr_static(df, delay_death)
#> severity_estimate severity_low severity_high
#> 1 0.1042 0.086 0.1245Hence in this particular simulation, the cfr_static()
method recovers the correct CFR of 10% (95% CI: 8.3-12.0%), whereas the
filtering method produces a biased estimate of 26.4% (17.6-37.0%).
Deaths reported but not recoveries
In an extreme scenario where recoveries are not reported, then we
effectively have the values of outcome_recovery generated
from a distribution with an infinite mean, and the above conclusions
will still apply, with the same bias for the filtering approach. In
particular, we would expect:
And hence the calculated CFR to incorrectly converge to 1 as the proportion of recoveries reported declines to 0.
Only total deaths reported
In some situations, we may have a time series of cases but not deaths. However, we can still use the earlier calculation to derive an unbiased CFR:
We can do this in cfr using the
estimate_outcomes() function to calculate the expected
number of cases with known fatal outcomes in the above denominator:
# Calculate total deaths and total cases
total_deaths <- sum(df$deaths)
total_cases <- sum(df$cases)
# Create data.frame with cases over time only
df_case <- df
df_case$deaths <- 0
# Calculate the expected number of known fatal outcomes over time
e_outcomes <- estimate_outcomes(df_case, delay_death)
# Calculate the CFR
total_deaths / (total_cases * tail(e_outcomes$u_t, 1))
#> [1] 0.1042066As before, this produces a point estimate of 10.4%, because it is the
same underlying method: the internal function code in
cfr_static(), which calls estimate_outcomes(),
also tallies up total death. An arguably more elegant approach is to
therefore add total deaths to the case data.frame, and use as an input
for cfr_static():
# Create data.frame with cases over time only
df_cases <- df
df_cases$deaths <- 0
# Add total deaths to the final row in the 'deaths' column
df_cases$deaths[nrow(df_cases)] <- sum(df$deaths)
# Calculate CFR
cfr_static(df_cases, delay_death)
#> severity_estimate severity_low severity_high
#> 1 0.1042 0.086 0.1245Only total cases and deaths reported
If only total cases and total deaths are known, it is not possible to adjust for delays to outcome. However, we can bound our estimate of CFR by two extreme scenarios. First, if the outbreak is over, and sufficient time has passed so that all fatal outcomes are now known, i.e.
then the CFR would be equal to:
In contrast, if the epidemic is rapidly growing and still in its early stages, then even an epidemic with a CFR of 1 may have only generated a very small number of fatal outcomes to date. Hence we have the following bounds on the possible CFR:
In other words, during a rapidly growing epidemic, we can only say that the CFR lies somewhere between the ratio of total deaths to total cases (as of the last known count) and 1 (the worst-case scenario).