Exploring History
Last updated on 2023-11-27 | Edit this page
Overview
Questions
- How can I identify old versions of files?
- How do I review my changes?
- How can I recover old versions of files?
Objectives
- Explain what the HEAD of a repository is and how to use it.
- Identify and use Git commit numbers.
- Compare various versions of tracked files.
- Restore old versions of files.
The HEAD
As we saw in the previous episode, we can refer to commits by their
identifiers. You can refer to the most recent commit of the
working directory by using the identifier HEAD.
We’ve been adding one line at a time to sitrep.Rmd, so
it’s easy to track our progress by looking, so let’s do that using our
HEADs. Before we start, let’s make a change to
sitrep.Rmd, adding yet another line.
R
usethis::edit_file("sitrep.Rmd")
OUTPUT
Comparison of attack rates in different age groups
This can identify priority groups for interventions
Maps illustrate the spread and impact of outbreak
Maps can aid in the identification of hotspotsSave the file.
Now, in the Terminal, let’s see what we get.
OUTPUT
diff --git a/sitrep.Rmd b/sitrep.Rmd
index b36abfd..0848c8d 100644
--- a/sitrep.Rmd
+++ b/sitrep.Rmd
@@ -1,3 +1,4 @@
Comparison of attack rates in different age groups
This can identify priority groups for interventions
Maps illustrate the spread and impact of outbreak
+Maps can aid in the identification of hotspots.which is the same as what you would get if you leave out
HEAD (try it). The real goodness in all this is when you
can refer to previous commits. We do that by adding ~1
(where “~” is “tilde”, pronounced [til-duh])
to refer to the commit one before HEAD.
If we want to see the differences between older commits we can use
git diff again, but with the notation HEAD~1,
HEAD~2, and so on, to refer to them:
OUTPUT
diff --git a/sitrep.Rmd b/sitrep.Rmd
index df0654a..b36abfd 100644
--- a/sitrep.Rmd
+++ b/sitrep.Rmd
@@ -1 +1,4 @@
Comparison of attack rates in different age groups
+This can identify priority groups for interventions
+Maps illustrate the spread and impact of outbreak
+Maps can aid in the identification of hotspotsShow changes in old commits
We could also use git show which shows us what changes
we made at an older commit as well as the commit message, rather than
the differences between a commit and our working directory that
we see by using git diff.
OUTPUT
commit f22b25e3233b4645dabd0d81e651fe074bd8e73b
Author: Vlad Dracula <vlad@tran.sylvan.ia>
Date: Thu Aug 22 09:51:46 2013 -0400
Start Sitrep with attack rate analysis
diff --git a/sitrep.Rmd b/sitrep.Rmd
new file mode 100644
index 0000000..df0654a
--- /dev/null
+++ b/sitrep.Rmd
@@ -0,0 +1 @@
+Comparison of attack rates in different age groupsIn this way, we can build up a chain of commits. The most recent end
of the chain is referred to as HEAD; we can refer to
previous commits using the ~ notation, so
HEAD~1 means “the previous commit”, while
HEAD~123 goes back 123 commits from where we are now.
Use commit unique ID
We can also refer to commits using those long strings of digits and
letters that git log displays. These are unique IDs for the
changes, and “unique” really does mean unique: every change to any set
of files on any computer has a unique 40-character identifier. Our first
commit was given the ID
f22b25e3233b4645dabd0d81e651fe074bd8e73b, so let’s try
this:
OUTPUT
diff --git a/sitrep.Rmd b/sitrep.Rmd
index df0654a..93a3e13 100644
--- a/sitrep.Rmd
+++ b/sitrep.Rmd
@@ -1 +1,4 @@
Comparison of attack rates in different age groups
+This can identify priority groups for interventions
+Maps illustrate the spread and impact of outbreak
+Maps can aid in the identification of hotspotsThat’s the right answer, but typing out random 40-character strings is annoying, so Git lets us use just the first few characters (typically seven for normal size projects):
OUTPUT
diff --git a/sitrep.Rmd b/sitrep.Rmd
index df0654a..93a3e13 100644
--- a/sitrep.Rmd
+++ b/sitrep.Rmd
@@ -1 +1,4 @@
Comparison of attack rates in different age groups
+This can identify priority groups for interventions
+Maps illustrate the spread and impact of outbreak
+Maps can aid in the identification of hotspotsRestore old versions
All right! So we can save changes to files and see what we’ve
changed. Now, how can we restore older versions of things? Let’s suppose
we change our mind about the last update to sitrep.Rmd (the
one about the “hotspots”).
git status now tells us that the file has been changed,
but those changes haven’t been staged:
OUTPUT
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: sitrep.Rmd
no changes added to commit (use "git add" and/or "git commit -a")We can put things back the way they were by using
git checkout:
Now, read the content in the file:
R
usethis::edit_file("sitrep.Rmd")
OUTPUT
Comparison of attack rates in different age groups
This can identify priority groups for interventions
Maps illustrate the spread and impact of outbreakAs you might guess from its name, git checkout checks
out (i.e., restores) an old version of a file. In this case, we’re
telling Git that we want to recover the version of the file recorded in
HEAD, which is the last saved commit. If we want to go back
even further, we can use a commit identifier instead:
Now, read the content in the file:
R
usethis::edit_file("sitrep.Rmd")
OUTPUT
Comparison of attack rates in different age groupsAsk the current status:
OUTPUT
On branch main
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: sitrep.Rmd
Notice that the changes are currently in the staging area. Again, we
can put things back the way they were by using
git checkout:
Don’t Lose Your HEAD
Above we used
to revert sitrep.Rmd to its state after the commit
f22b25e. But be careful! The command checkout
has other important functionalities and Git will misunderstand your
intentions if you are not accurate with the typing. For example, if you
forget sitrep.Rmd in the previous command.
ERROR
Note: checking out 'f22b25e'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b <new-branch-name>
HEAD is now at f22b25e Start Sitrep with attack rate analysisThe “detached HEAD” is like “look, but don’t touch” here, so you
shouldn’t make any changes in this state. After investigating your
repo’s past state, reattach your HEAD with
git checkout main.
It’s important to remember that we must use the commit number that
identifies the state of the repository before the change we’re
trying to undo. A common mistake is to use the number of the commit in
which we made the change we’re trying to discard. In the example below,
we want to retrieve the state from before the most recent commit
(HEAD~1), which is commit f22b25e:

So, to put it all together, here’s how Git works in cartoon form:

Simplifying the Common Case
If you read the output of git status carefully, you’ll
see that it includes this hint:
OUTPUT
(use "git checkout -- <file>..." to discard changes in working directory)As it says, git checkout without a version identifier
restores files to the state saved in HEAD. The double dash
-- is needed to separate the names of the files being
recovered from the command itself: without it, Git would try to use the
name of the file as the commit identifier.
The fact that files can be reverted one by one tends to change the way people organize their work. If everything is in one large document, it’s hard (but not impossible) to undo changes to the introduction without also undoing changes made later to the conclusion. If the introduction and conclusion are stored in separate files, on the other hand, moving backward and forward in time becomes much easier.
Challenges
Recovering Older Versions of a File
Jennifer has made changes to the Python script that she has been working on for weeks, and the modifications she made this morning “broke” the script and it no longer runs. She has spent ~ 1hr trying to fix it, with no luck…
Luckily, she has been keeping track of her project’s versions using
Git! Which commands below will let her recover the last committed
version of her Python script called data_cruncher.py?
$ git checkout HEAD$ git checkout HEAD data_cruncher.py$ git checkout HEAD~1 data_cruncher.py$ git checkout <unique ID of last commit> data_cruncher.pyBoth 2 and 4
The answer is (5)-Both 2 and 4.
The checkout command restores files from the repository,
overwriting the files in your working directory. Answers 2 and 4 both
restore the latest version in the repository of the
file data_cruncher.py. Answer 2 uses HEAD to
indicate the latest, whereas answer 4 uses the unique ID of the
last commit, which is what HEAD means.
Answer 3 gets the version of data_cruncher.py from the
commit before HEAD, which is NOT what we
wanted.
Answer 1 can be dangerous! Without a filename,
git checkout will restore all files in the
current directory (and all directories below it) to their state at the
commit specified. This command will restore
data_cruncher.py to the latest commit version, but it will
also restore any other files that are changed to that version,
erasing any changes you may have made to those files! As discussed
above, you are left in a detached HEAD state, and
you don’t want to be there.
Reverting a Commit
Jennifer is collaborating with colleagues on her Python script. She
realizes her last commit to the project’s repository contained an error,
and wants to undo it. Jennifer wants to undo correctly so everyone in
the project’s repository gets the correct change. The command
git revert [erroneous commit ID] will create a new commit
that reverses the erroneous commit.
The command git revert is different from
git checkout [commit ID] because git checkout
returns the files not yet committed within the local repository to a
previous state, whereas git revert reverses changes
committed to the local and project repositories.
Below are the right steps and explanations for Jennifer to use
git revert, what is the missing command?
________ # Look at the git history of the project to find the commit IDCopy the ID (the first few characters of the ID, e.g. 0b1d055).
git revert [commit ID]Type in the new commit message.
Save and close
The command git log lists project history with commit
IDs.
The command git show HEAD shows changes made at the
latest commit, and lists the commit ID; however, Jennifer should
double-check it is the correct commit, and no one else has committed
changes to the repository.
These commands are so similar!
Commands like git checkout and git revert
are useful but so similar that it’s very easy to mix them up!
With the concepts learned in this episode, we invite you to read this chapter on undoing commits and changes.
Understanding Workflow and History
What is the output of the last command in
BASH
$ cd cases
$ echo "Data is messy and full of typos" > clean.Rmd #this adds a line of text in clean.Rmd
$ git add clean.Rmd
$ echo "Data is too long to be suitable to print" >> clean.Rmd
$ git commit -m "Comment on Data as an unsuitable print"
$ git checkout HEAD clean.Rmd
$ cat clean.Rmd #this will print the contents of clean.Rmd to the screen- ```output Data is too long to be suitable to print
2. ```output
Data is messy and full of typos- ```output Data is messy and full of typos Data is too long to be suitable to print
4. ```output
Error because you have changed clean.Rmd without committing the changesThe answer is 2.
The command git add clean.Rmd places the current version
of clean.Rmd into the staging area. The changes to the file
from the second echo command are only applied to the
working copy, not the version in the staging area.
So, when
git commit -m "Comment on Data as an unsuitable print" is
executed, the version of clean.Rmd committed to the
repository is the one from the staging area and has only one line.
At this time, the working copy still has the second line (and
git status will show that the file is modified). However,
git checkout HEAD clean.Rmd replaces the working copy with
the most recently committed version of clean.Rmd.
So, cat clean.Rmd will output
OUTPUT
Data is messy and full of typos.Checking Understanding of
git diff
Consider this command: git diff HEAD~9 sitrep.Rmd. What
do you predict this command will do if you execute it? What happens when
you do execute it? Why?
Try another command, git diff [ID] sitrep.Rmd, where
[ID] is replaced with the unique identifier for your most recent commit.
What do you think will happen, and what does happen?
Getting Rid of Staged Changes
git checkout can be used to restore a previous commit
when unstaged changes have been made, but will it also work for changes
that have been staged but not committed? Make a change to
sitrep.Rmd, add that change using git add,
then use git checkout to see if you can remove your
change.
After adding a change, git checkout can not be used
directly. Let’s look at the output of git status:
OUTPUT
On branch main
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: sitrep.Rmd
Note that if you don’t have the same output you may either have forgotten to change the file, or you have added it and committed it.
Using the command git checkout -- sitrep.Rmd now does
not give an error, but it does not restore the file either. Git
helpfully tells us that we need to use git reset first to
unstage the file:
OUTPUT
Unstaged changes after reset:
M sitrep.RmdNow, git status gives us:
OUTPUT
On branch main
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: sitrep.Rmd
no changes added to commit (use "git add" and/or "git commit -a")This means we can now use git checkout to restore the
file to the previous commit:
OUTPUT
On branch main
nothing to commit, working tree cleanExplore and Summarize Histories
Exploring history is an important part of Git, and often it is a challenge to find the right commit ID, especially if the commit is from several months ago.
Imagine the cases project has more than 50 files. You
would like to find a commit that modifies some specific text in
sitrep.Rmd. When you type git log, a very long
list appeared. How can you narrow down the search?
Recall that the git diff command allows us to explore
one specific file, e.g., git diff sitrep.Rmd. We can apply
a similar idea here.
Unfortunately some of these commit messages are very ambiguous, e.g.,
update files. How can you search through these files?
Both git diff and git log are very useful
and they summarize a different part of the history for you. Is it
possible to combine both? Let’s try the following:
You should get a long list of output, and you should be able to see both commit messages and the difference between each commit.
Question: What does the following command do?
Checklist
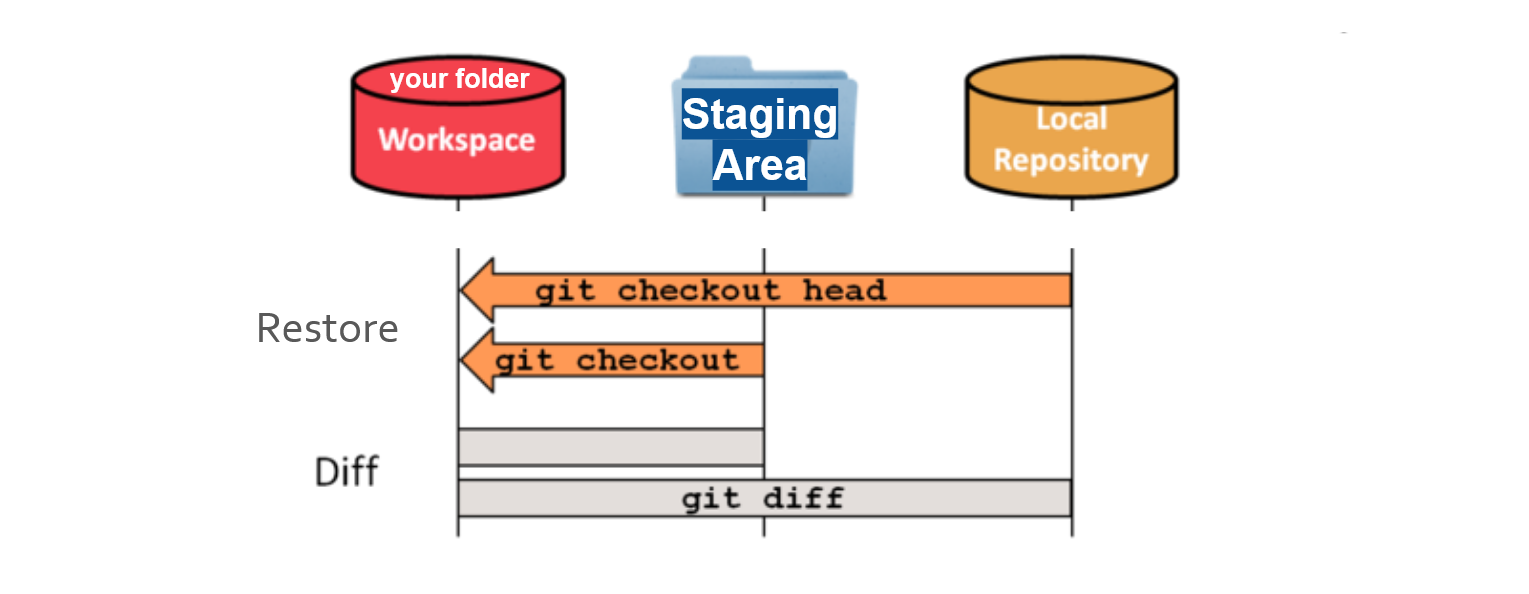
git diff to compare changes
since last commit or between commits. Use git checkout to
undo changes by restoring the staging area (committed changes) or the
local repository (last commit)Key Points
-
git diffdisplays differences between commits. -
git checkoutrecovers old versions of files.