Epidemic final size calculations are sensitive to input data such as the \(R_0\) of the infection. Such values can often be uncertain in the early stages of an outbreak. This uncertainty can be included in final size calculations by running final_size() for values drawn from a distribution, and summarising the outcomes.
New to finalsize? It may help to read the “Get started”, “Modelling heterogeneous contacts”, or “Modelling heterogeneous susceptibility” vignettes first!
Use case
The infection parameter (\(R_0\)) is uncertain. We want to know how much variation this could cause in the estimated final size of the epidemic.
Getting \(R_0\), contact and demography data, and susceptibility
This example uses social contact data from the POLYMOD project (Mossong et al. 2008) to estimate the final size of an epidemic in the U.K. These data are provided with the socialmixr package.
These data are handled just as in the “Get started” vignette. This example also considers an infection with an \(R_0\) of 1.5.
Code
# get UK polymod data from socialmixr
polymod <- socialmixr::polymod
contact_data <- socialmixr::contact_matrix(
polymod,
countries = "United Kingdom",
age.limits = c(0, 5, 18, 40, 65),
symmetric = TRUE
)
# get the contact matrix and demography data
contact_matrix <- t(contact_data$matrix)
demography_vector <- contact_data$demography$population
# scale the contact matrix so the largest eigenvalue is 1.0
contact_matrix <- contact_matrix / max(Re(eigen(contact_matrix)$values))
# divide each row of the contact matrix by the corresponding demography
contact_matrix <- contact_matrix / demography_vector
n_demo_grps <- length(demography_vector)Code
# mean R0 is 1.5
r0_mean <- 1.5For simplicity, this example considers a scenario in which susceptibility to infection does not vary.
Code
# susceptibility is uniform
susc_uniform <- matrix(
data = 1,
nrow = n_demo_grps,
ncol = 1L
)
# p_susceptibility is uniform
p_susc_uniform <- susc_uniformRunning final_size over \(R_0\) samples
The basic reproduction number \(R_0\) of an infection might be uncertain in the early stages of an epidemic. This uncertainty can be modelled by running final_size() multiple times for the same contact, demography, and susceptibility data, while sampling \(R_0\) values from a distribution.
This example assumes that the \(R_0\) estimate, and the uncertainty around that estimate, is provided as the mean and standard deviation of a normal distribution.
This example considers a normal distribution \(N(\mu = 1.5, \sigma = 0.1)\), for an \(R_0\) of 1.5. We can draw 1,000 \(R_0\) samples from this distribution and run final_size() on the contact data and demography data for each sample.
This is quick, as finalsize is an Rcpp package with a C++ backend.
Code
# create an R0 samples vector
r0_samples <- rnorm(n = 1000, mean = r0_mean, sd = 0.1)Iterate final_size()
Code
# run final size on each sample with the same data
final_size_data <- Map(
r0_samples, seq_along(r0_samples),
f = function(r0, i) {
# the i-th final size estimate
fs <- final_size(
r0 = r0,
contact_matrix = contact_matrix,
demography_vector = demography_vector,
susceptibility = susc_uniform,
p_susceptibility = p_susc_uniform
)
fs$replicate <- i
fs$r0_estimate <- r0
fs
}
)
# combine data
final_size_data <- Reduce(x = final_size_data, f = rbind)
# order age groups
final_size_data$demo_grp <- factor(
final_size_data$demo_grp,
levels = contact_data$demography$age.group
)
# examine some replicates in the data
head(final_size_data, 15)
#> demo_grp susc_grp susceptibility p_infected replicate r0_estimate
#> 1 [0,5) susc_grp_1 1 0.3060666 1 1.336523
#> 2 [5,18) susc_grp_1 1 0.5600211 1 1.336523
#> 3 [18,40) susc_grp_1 1 0.4077367 1 1.336523
#> 4 [40,65) susc_grp_1 1 0.3431819 1 1.336523
#> 5 65+ susc_grp_1 1 0.2152010 1 1.336523
#> 6 [0,5) susc_grp_1 1 0.4251326 2 1.515086
#> 7 [5,18) susc_grp_1 1 0.6982753 2 1.515086
#> 8 [18,40) susc_grp_1 1 0.5482161 2 1.515086
#> 9 [40,65) susc_grp_1 1 0.4737790 2 1.515086
#> 10 65+ susc_grp_1 1 0.3119129 2 1.515086
#> 11 [0,5) susc_grp_1 1 0.2958595 3 1.322917
#> 12 [5,18) susc_grp_1 1 0.5465699 3 1.322917
#> 13 [18,40) susc_grp_1 1 0.3951655 3 1.322917
#> 14 [40,65) susc_grp_1 1 0.3318586 3 1.322917
#> 15 65+ susc_grp_1 1 0.2072746 3 1.322917Code
library(tibble)
library(dplyr)
library(tidyr)
library(purrr)
library(forcats)
final_size_data <-
# create a dataframe with values from a vector
tibble(r0 = r0_samples) %>%
rownames_to_column() %>%
# map the function final_size() to all the r0 values
# with the same set of arguments
# with {purrr}
mutate(
temp = map(
.x = r0,
.f = final_size,
contact_matrix = contact_matrix,
demography_vector = demography_vector,
susceptibility = susc_uniform,
p_susceptibility = p_susc_uniform
)
) %>%
# unnest all the dataframe outputs in temp
unnest(temp) %>%
# relevel the factor variable
mutate(
demo_grp = fct_relevel(
demo_grp,
contact_data %>%
pluck("demography") %>%
pluck("age.group")
)
)
head(final_size_data, 15)
#> # A tibble: 15 × 6
#> rowname r0 demo_grp susc_grp susceptibility p_infected
#> <chr> <dbl> <fct> <chr> <dbl> <dbl>
#> 1 1 1.34 [0,5) susc_grp_1 1 0.306
#> 2 1 1.34 [5,18) susc_grp_1 1 0.560
#> 3 1 1.34 [18,40) susc_grp_1 1 0.408
#> 4 1 1.34 [40,65) susc_grp_1 1 0.343
#> 5 1 1.34 65+ susc_grp_1 1 0.215
#> 6 2 1.52 [0,5) susc_grp_1 1 0.425
#> 7 2 1.52 [5,18) susc_grp_1 1 0.698
#> 8 2 1.52 [18,40) susc_grp_1 1 0.548
#> 9 2 1.52 [40,65) susc_grp_1 1 0.474
#> 10 2 1.52 65+ susc_grp_1 1 0.312
#> 11 3 1.32 [0,5) susc_grp_1 1 0.296
#> 12 3 1.32 [5,18) susc_grp_1 1 0.547
#> 13 3 1.32 [18,40) susc_grp_1 1 0.395
#> 14 3 1.32 [40,65) susc_grp_1 1 0.332
#> 15 3 1.32 65+ susc_grp_1 1 0.207Visualise uncertainty in final size
Code
ggplot(final_size_data) +
stat_summary(
aes(
demo_grp, p_infected
),
fun = mean,
fun.min = function(x) {
quantile(x, 0.05)
},
fun.max = function(x) {
quantile(x, 0.95)
}
) +
scale_y_continuous(
labels = scales::percent,
limits = c(0.25, 1)
) +
theme_classic() +
theme(
legend.position = "top",
legend.key.height = unit(2, "mm"),
legend.title = ggtext::element_markdown(
vjust = 1
)
) +
coord_cartesian(
expand = TRUE
) +
labs(
x = "Age group",
y = "% Infected"
)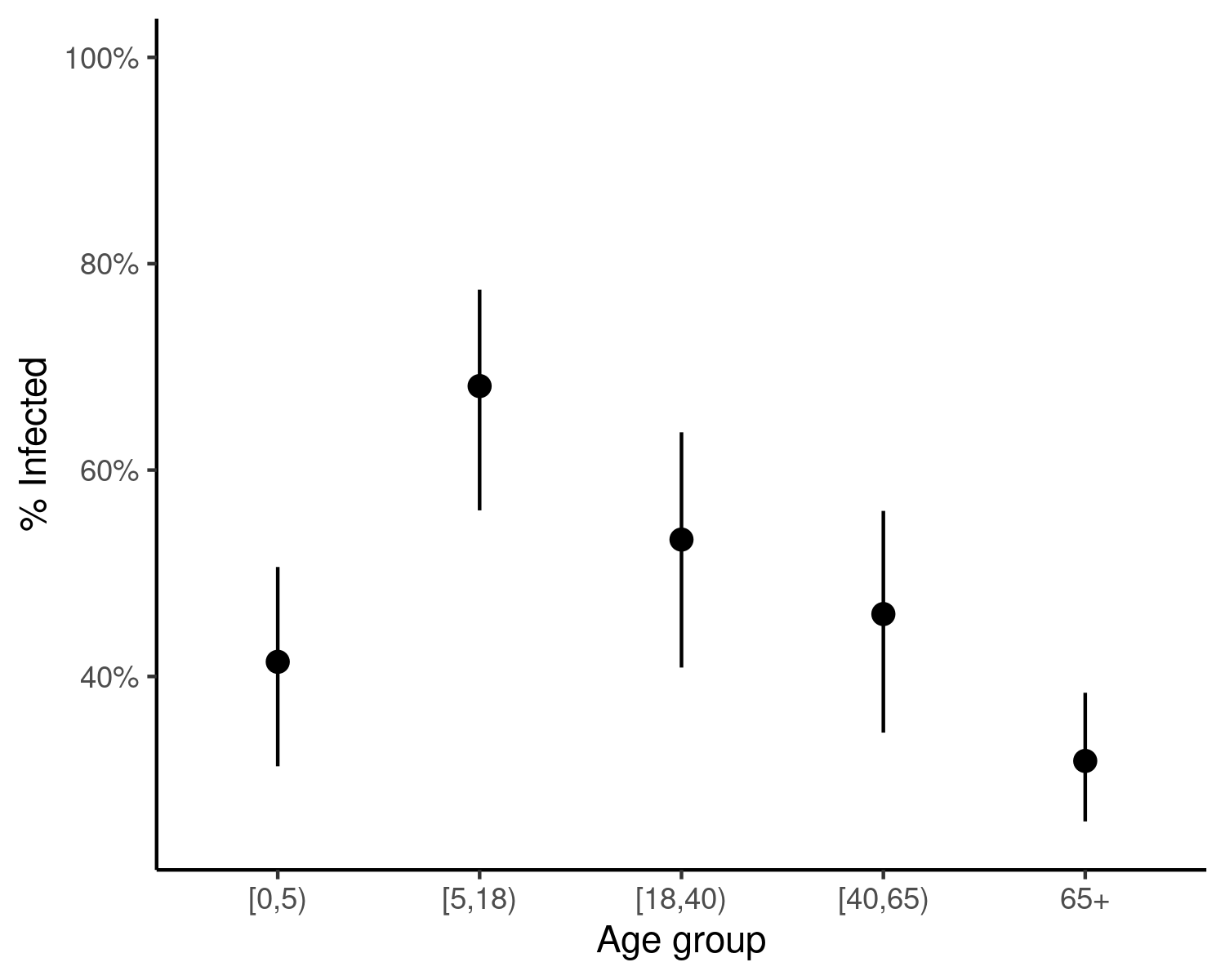
Figure 1: Estimated ranges of the final size of a hypothetical SIR epidemic in age groups of the U.K. population, when the \(R_0\) is estimated to be 1.5, with a standard deviation around this estimate of 0.1. In this example, relatively low uncertainty in \(R_0\) estimates can also lead to uncertainty in the estimated final size of the epidemic. Points represent means, while ranges extend between the 5th and 95th percentiles.