Modelling heterogeneous susceptibility
Source:vignettes/varying_susceptibility.Rmd
varying_susceptibility.RmdPopulations are often heterogeneous in their susceptibility to infection following exposure, independent of the exposure risk that comes from different social contact patterns. Such heterogeneity may be age-dependent and vary between age groups. It may also vary within age groups due to prior infection resulting in immunity or due to immunisation. Combinations of within- and between-group variation in susceptibility may also occur, and can be incorporated into final size calculations (Miller 2012).
New to finalsize? It may help to read the “Get started” and “Modelling heterogeneous contacts” vignettes first!
Use case
There is substantial heterogeneity in susceptibility to infection in a population. We want to know how this heterogeneity could affect the final size of the epidemic.
What we have
- In addition to the infection \(R_0\), demography data, and social contact data;
- Data on within- and between-group variation in susceptibility to the infection; and
- Data on the proportion (or probability) of individuals in any demographic group in a specific susceptibility (or risk) group.
Primer on heterogeneous susceptibility
A working definition of susceptibility is the probability of becoming infected on contact with an infectious person.
Age-specific factors influencing the susceptibility of individuals include, but are not limited to, direct (immunological) susceptibility to infection upon exposure (e.g., due to natural susceptibility from previous infections, differences in vaccination status), and age-specific heterogeneous risk behaviour (Franco et al. 2022).
For example, for SARS-CoV-2, children are less susceptible to it than adults. Decreased susceptibility could result from immune cross-protection from other coronaviruses (Huang et al. 2020), or from non-specific protection resulting from recent infection by other respiratory viruses (Cowling et al. 2012), which children experience more frequently than adults (Tsagarakis et al. 2018; Davies et al. 2020).
Code
# load finalsize
library(finalsize)
library(socialmixr)
library(ggplot2)
library(colorspace)Getting \(R_0\) and contact and demography data
This example uses social contact data from the POLYMOD project (Mossong et al. 2008) to estimate the final size of an epidemic in the U.K. These data are provided with the socialmixr package.
These data are handled just as in the “Get started” vignette, and the code is not displayed here. This example also considers a disease with an \(R_0\) of 1.5.
Code
# get UK polymod data
polymod <- socialmixr::polymod
contact_data <- socialmixr::contact_matrix(
polymod,
countries = "United Kingdom",
age.limits = c(0, 5, 18, 40, 65),
symmetric = TRUE
)
# get the contact matrix and demography data
contact_matrix <- t(contact_data$matrix)
demography_vector <- contact_data$demography$population
# scale the contact matrix so the largest eigenvalue is 1.0
contact_matrix <- contact_matrix / max(Re(eigen(contact_matrix)$values))
# divide each row of the contact matrix by the corresponding demography
contact_matrix <- contact_matrix / demography_vector
n_demo_grps <- length(demography_vector)Code
r0 <- 1.5Susceptibility variation between age groups
This example considers a scenario in which susceptibility to infection varies between age groups, but not within groups. In this example, susceptibility to infection increases with age.
This can be modelled as a susceptibility matrix with higher values for the 40 – 64 and 65 and over age groups, and relatively lower values for other groups.
Code
Note that the susceptibility matrix (susc_variable) still has only one column. The next example will show why this is modelled as a matrix.
The corresponding demography-susceptibility group distribution matrix is a one-column matrix of 1.0s: there is no variation in susceptibility within groups.
Code
p_susc_uniform <- matrix(
data = 1.0,
nrow = n_demo_grps,
ncol = n_susc_groups
)Calculate the effective \(R_0\)
The effective \(R_0\) of the epidemic can often be different in a population with heterogeneous social contacts and heterogeneous susceptibility, both within and between groups.
The effective \(R_0\) is called \(R_{\text{eff}}\) and can be calculated using the function r_eff().
Code
# calculate the effective R0 using `r_eff()`
r_eff(
r0 = r0,
contact_matrix = contact_matrix,
demography_vector = demography_vector,
susceptibility = susc_variable,
p_susceptibility = p_susc_uniform
)
#> [1] 1.25815This calculation shows that the user-specified \(R_0\) = 1.5 gives an \(R_{\text{eff}}\) of \(\approx\) 1.258 in this population, because not all individuals are fully susceptible to infection.
Calculate the final epidemic size
We can compare the final size in a population with heterogeneous susceptibility against that of a population with a uniform, high susceptibility.
Code
# run final_size with default solvers and control options
# final size with heterogeneous susceptibility
final_size_heterog <- final_size(
r0 = r0,
contact_matrix = contact_matrix,
demography_vector = demography_vector,
susceptibility = susc_variable,
p_susceptibility = p_susc_uniform
)Code
# prepare uniform susceptibility matrix
susc_uniform <- matrix(1.0, nrow = n_demo_grps, ncol = n_susc_groups)
# run final size with uniform susceptibility
final_size_uniform <- final_size(
r0 = r0,
contact_matrix = contact_matrix,
demography_vector = demography_vector,
susceptibility = susc_uniform,
p_susceptibility = p_susc_uniform
)Visualise the effect of modelling age-dependent susceptibility against uniform susceptibility for all age groups.
Code
# assign scenario name and join data
final_size_heterog$scenario <- "heterogeneous"
final_size_uniform$scenario <- "uniform"
# join dataframes
final_size_data <- rbind(
final_size_heterog,
final_size_uniform
)
# prepare age group order
final_size_data$demo_grp <- factor(
final_size_data$demo_grp,
levels = contact_data$demography$age.group
)
# examine the combined data
final_size_data
#> demo_grp susc_grp susceptibility p_infected scenario
#> 1 [0,5) susc_grp_1 0.75 0.2288298 heterogeneous
#> 2 [5,18) susc_grp_1 0.80 0.4639058 heterogeneous
#> 3 [18,40) susc_grp_1 0.85 0.3517122 heterogeneous
#> 4 [40,65) susc_grp_1 0.90 0.3119224 heterogeneous
#> 5 65+ susc_grp_1 1.00 0.2163372 heterogeneous
#> 6 [0,5) susc_grp_1 1.00 0.4160682 uniform
#> 7 [5,18) susc_grp_1 1.00 0.6888703 uniform
#> 8 [18,40) susc_grp_1 1.00 0.5379381 uniform
#> 9 [40,65) susc_grp_1 1.00 0.4639496 uniform
#> 10 65+ susc_grp_1 1.00 0.3042623 uniformCode
ggplot(final_size_data) +
geom_col(
aes(
x = demo_grp, y = p_infected,
fill = scenario
),
col = "black",
position = position_dodge(
width = 0.75
)
) +
expand_limits(
x = c(0.5, length(unique(final_size_data$demo_grp)) + 0.5)
) +
scale_fill_discrete_qualitative(
palette = "Cold",
name = "Population susceptibility",
labels = c("Heterogeneous", "Uniform")
) +
scale_y_continuous(
labels = scales::percent,
limits = c(0, 1)
) +
theme_classic() +
theme(
legend.position = "top",
legend.key.height = unit(2, "mm"),
legend.title = ggtext::element_markdown(
vjust = 1
)
) +
coord_cartesian(
expand = FALSE
) +
labs(
x = "Age group",
y = "% Infected"
)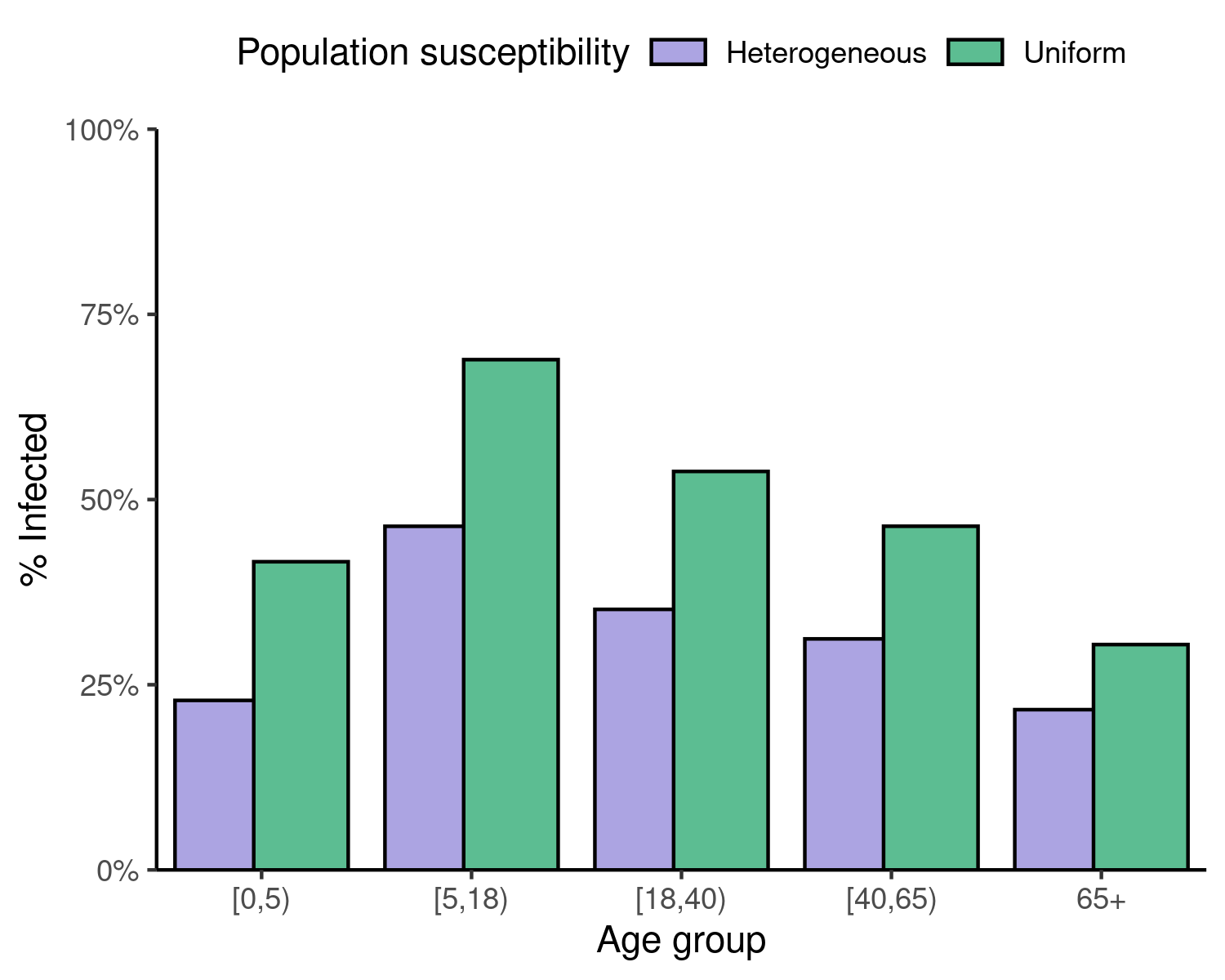
Figure 1: Final sizes of epidemics in populations wherein susceptibility to the infection is either uniform (green), or heterogeneous (purple), with older individuals more susceptible to the infection.
Note that, as shown in this example, a population with heterogeneous susceptibility is always expected to have a lower final epidemic size overall than an otherwise identical population that is fully susceptible.
This illustrates the broader point that infections in any one age group are not independent of the infections in other age groups. This is due to direct or indirect social contacts between age groups.
Reducing the susceptibility (and thus infections) of one age group can indirectly help to reduce infections in other age groups as well, because the overall level of epidemic transmission will be reduced.
Susceptibility variation within and between age groups
This example considers a scenario in which susceptibility to infection varies within and between age groups. Immunisation against infection through an intervention campaign is a common cause of within-age group variation in susceptibility, and this example can be thought of as examining the effect of vaccination.
The effect of immunisation on susceptibility can be modelled as a reduction of the initial susceptibility of each age group. This is done by adding a column to the susceptibility matrix, with lower values than the first column.
Code
# immunisation effect
immunisation_effect <- 0.25This example considers a modest 25% reduction in susceptibility due to vaccination.
Code
Note that because there are two susceptibility groups, the susceptibility matrix has two columns. The corresponding demography-susceptibility distribution matrix must also have two columns!
We also need to model the proportion of each age group that has been immunised, and which therefore has lower susceptibility to the infection. To do this, we can modify the demography-susceptibility distribution matrix.
This example model considers half of each age group to be in the immunised and non-immunised groups.
In general terms, this could be interpreted as the rate of vaccine uptake, or as the effect of existing immunity from previous infection by a similar pathogen.
Getting data on within-group susceptibility differences
For within-group differences in susceptibility, such as due to immunisation, users could obtain this information from age-specific vaccination uptake statistics from national governments (here, the UK). When antibody response decays are known for an immunisation course (Iyer et al. 2020), more detailed statistics on the percentage of people vaccinated in the preceding few months only (here, in the UK), may be more informative.
Code
Recall that each row of the demography-susceptibility distribution matrix must always sum to 1.0!
Code
# we run final size over all r0 values
final_size_immunised <- final_size(
r0 = r0,
contact_matrix = contact_matrix,
demography_vector = demography_vector,
susceptibility = susc_immunised,
p_susceptibility = p_susc_immunised
)The effect of immunisation (or some other reduction in susceptibility) can be visualised by comparing the proportion of the immunised and un-immunised groups that are infected.
Code
# add scenario identifier
final_size_immunised$scenario <- "immunisation"
# prepare age group order
final_size_heterog$demo_grp <- factor(
final_size_heterog$demo_grp,
levels = contact_data$demography$age.group
)
final_size_immunised$demo_grp <- factor(
final_size_immunised$demo_grp,
levels = contact_data$demography$age.group
)
# examine the data
final_size_immunised
#> demo_grp susc_grp susceptibility p_infected scenario
#> 1 [0,5) Un-immunised 0.7500 0.10882106 immunisation
#> 2 [5,18) Un-immunised 0.8000 0.25096327 immunisation
#> 3 [18,40) Un-immunised 0.8500 0.17473366 immunisation
#> 4 [40,65) Un-immunised 0.9000 0.15172135 immunisation
#> 5 65+ Un-immunised 1.0000 0.10075783 immunisation
#> 6 [0,5) Immunised 0.5625 0.08277964 immunisation
#> 7 [5,18) Immunised 0.6000 0.19484900 immunisation
#> 8 [18,40) Immunised 0.6375 0.13414414 immunisation
#> 9 [40,65) Immunised 0.6750 0.11609844 immunisation
#> 10 65+ Immunised 0.7500 0.07656251 immunisationCompare scenarios in which susceptibility is heterogeneous between groups, against the immunisation scenario in which susceptibility also varies within groups.
Code
ggplot(final_size_immunised) +
geom_col(
data = final_size_heterog,
aes(
x = demo_grp, y = p_infected,
fill = "baseline",
colour = "baseline"
),
width = 0.75,
show.legend = TRUE
) +
geom_col(
aes(
x = demo_grp, y = p_infected,
fill = susc_grp
),
col = "black",
position = position_dodge()
) +
facet_grid(
cols = vars(scenario),
labeller = labeller(
scenario = c(
heterogeneous = "Between groups only",
immunisation = "Within & between groups"
)
)
) +
expand_limits(
x = c(0.5, length(unique(final_size_immunised$demo_grp)) + 0.5)
) +
scale_fill_discrete_qualitative(
palette = "Dynamic",
rev = TRUE,
limits = c("Immunised", "Un-immunised"),
name = "Immunisation scenario",
na.value = "lightgrey"
) +
scale_colour_manual(
values = "black",
name = "No immunisation",
labels = "Susceptibility homogeneous\nwithin groups"
) +
scale_y_continuous(
labels = scales::percent,
limits = c(0, 0.5)
) +
theme_classic() +
theme(
legend.position = "bottom",
legend.key.height = unit(2, "mm"),
legend.title = ggtext::element_markdown(
vjust = 1
),
strip.background = element_blank(),
strip.text = element_text(
face = "bold",
size = 11
)
) +
guides(
colour = guide_legend(
override.aes = list(fill = "lightgrey"),
title.position = "top",
order = 1
),
fill = guide_legend(
nrow = 2,
title.position = "top",
order = 2
)
) +
coord_cartesian(
expand = FALSE
) +
labs(
x = "Age group",
y = "% Infected",
title = "Heterogeneous susceptibility",
fill = "Immunisation\nscenario"
)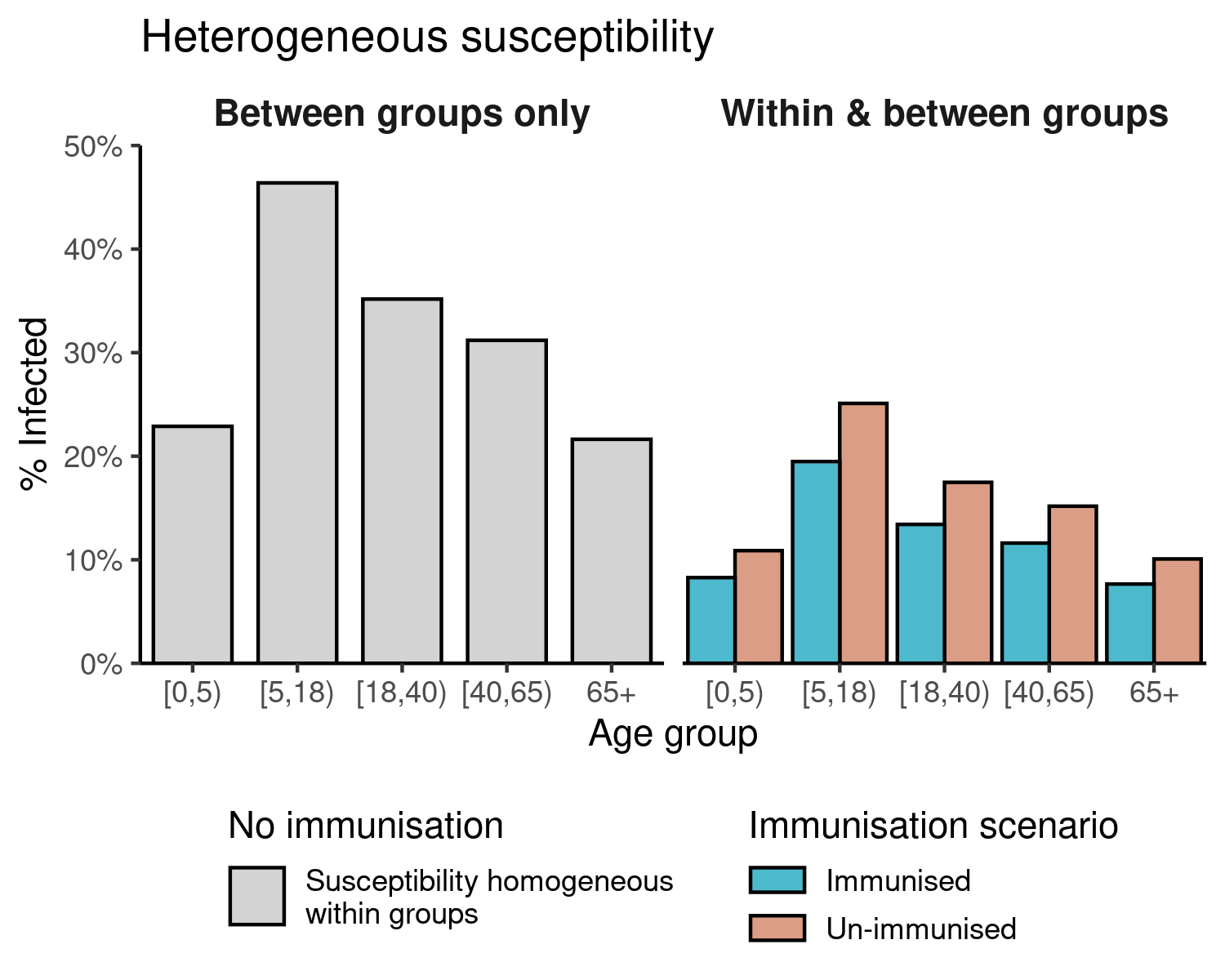
Figure 2: Final size of an SIR epidemic with \(R_0\) = 1.5, in a population wherein 50% of each age group is immunised against the infection. The immunisation is assumed to reduce the initial susceptibility of each age group by 25%. This leads to both within- and between-group heterogeneity in susceptibility. Vaccinating even 50% of each age group can substantially reduce the epidemic final size in comparison with a scenario in which there is no immunisation (grey). Note that the final sizes in this figure are all below 50%.
Heterogeneous susceptibility without social contact heterogeneity
finalsize can also account for heterogeneous susceptibilities without having to include heterogeneity in social contact patterns. This may be useful when calculating the final epidemic size without a good estimate of social contact patterns available.
This is done in a similar way as in the “Get started” vignette, but with susceptibility and p_susceptibility passed as \(N\)-column matrices, referring to the susceptibilities of the \(N\) susceptibility groups, and the proportions of the population that are in these groups, respectively.
This example considers pandemic influenza with an \(R_0\) of 1.5, affecting the U.K population of 67 million which is assumed to mix uniformly, but which has two distinct susceptibility groups, with susceptibility values of 1.0 (70% of the population), and 0.7 (30% of the population).
Code
# define r0
r0 <- 1.5
# define UK population size and prepare contact matrix
uk_pop <- 67 * 1e6
contact_matrix <- matrix(1.0) / uk_pop
# define susceptibility matrix
susceptibility <- matrix(c(1.0, 0.7), nrow = 1, ncol = 2)
# define p_susceptibility
p_susceptibility <- matrix(c(0.7, 0.3), nrow = 1, ncol = 2)
# running final_size()
final_size(
r0 = r0,
demography_vector = uk_pop,
contact_matrix = contact_matrix,
susceptibility = susceptibility,
p_susceptibility = p_susceptibility
)
#> demo_grp susc_grp susceptibility p_infected
#> 1 demo_grp_1 susc_grp_1 1.0 0.5083807
#> 2 demo_grp_1 susc_grp_2 0.7 0.3916685