Estimación de las distribuciones de rezagos epidemiológicos: Enfermedad X
Última actualización: 2026-04-28 | Mejora esta página
Hoja de ruta
Preguntas
- ¿Cómo responder ante un brote de una enfermedad desconocida?
Objetivos
Al final de este taller usted podrá:
Comprender los conceptos clave de las distribuciones de rezagos epidemiológicos para la Enfermedad X.
Comprender las estructuras de datos y las herramientas para el análisis de datos de rastreo de contactos.
Aprender a ajustar las estimaciones del intervalo serial y el período de incubación de la Enfermedad X teniendo en cuenta la censura por intervalo utilizando un marco de trabajo Bayesiano.
Aprender a utilizar estos parámetros para informar estrategias de control en un brote de un patógeno desconocido.
1. Introducción
La Enfermedad X representa un hipotético, pero plausible, brote de una enfermedad infecciosa en el futuro. Este término fue acuñado por la Organización Mundial de la Salud (OMS) y sirve como un término general para un patógeno desconocido que podría causar una epidemia grave a nivel internacional. Este concepto representa la naturaleza impredecible de la aparición de enfermedades infecciosas y resalta la necesidad de una preparación global y mecanismos de respuesta rápida. La Enfermedad X simboliza el potencial de una enfermedad inesperada y de rápida propagación, y resalta la necesidad de sistemas de salud flexibles y adaptables, así como capacidades de investigación para identificar, comprender y combatir patógenos desconocidos.
En esta práctica, va a aprender a estimar los rezagos epidemiológicos, el tiempo entre dos eventos epidemiológicos, utilizando un conjunto de datos simulado de la Enfermedad X.
La Enfermedad X es causada por un patógeno desconocido y se transmite directamente de persona a persona. Específicamente, la practica se centrará en estimar el período de incubación y el intervalo serial.
2. Agenda
Parte 1. Individual o en grupo.
Parte 2. En grupos de 6 personas. Construir estrategia de rastreo de contactos y aislamiento y preparar presentación de máximo 10 mins.
3. Conceptos claves
3.1. Rezagos epidemiológicos: Período de incubación e intervalo serial
En epidemiología, las distribuciones de rezagos se refieren a los retrasos temporales entre dos eventos clave durante un brote. Por ejemplo: el tiempo entre el inicio de los síntomas y el diagnóstico, el tiempo entre la aparición de síntomas y la muerte, entre muchos otros.
Este taller se enfocará en dos rezagos clave conocidos como el período de incubación y el intervalo serial. Ambos son cruciales para informar la respuesta de salud pública.
El período de incubación es el tiempo entre la infección y la aparición de síntomas.
El intervalo serial es el tiempo entre la aparición de síntomas entre el caso primario y secundario.
La relación entre estos parámetros tiene un impacto en si la enfermedad se transmite antes (transmisión pre-sintomática) o después de que los síntomas (transmisión sintomática) se hayan desarrollado en el caso primario (Figura 1).
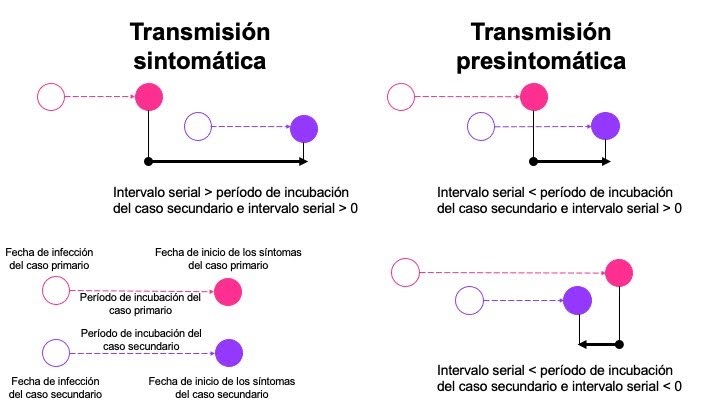
Figura 1. Relación entre el período de incubación y el intervalo serial en el momento de la transmisión (Adaptado de Nishiura et al. 2020)
3.2. Distribuciones comunes de rezagos y posibles sesgos
3.2.1 Sesgos potenciales
Cuando se estiman rezagos epidemiológicos, es importante considerar posibles sesgos:
Censura significa que sabemos que un evento ocurrió, pero no sabemos exactamente cuándo sucedió. La mayoría de los datos epidemiológicos están “doblemente censurados” debido a la incertidumbre que rodea tanto los tiempos de eventos primarios como secundarios. No tener en cuenta la censura puede llevar a estimaciones sesgadas de la desviación estándar del resago (Park et al. en progreso).
Truncamiento a la derecha es un tipo de sesgo de muestreo relacionado con el proceso de recolección de datos. Surge porque solo se pueden observar los casos que han sido reportados. No tener en cuenta el truncamiento a la derecha durante la fase de crecimiento de una epidemia puede llevar a una subestimación del rezago medio (Park et al. en progreso).
El sesgo dinámico (o de fase epidémica) es otro tipo de sesgo de muestreo. Afecta a los datos retrospectivos y está relacionado con la fase de la epidemia: durante la fase de crecimiento exponencial, los casos que desarrollaron síntomas recientemente están sobrerrepresentados en los datos observados, mientras que durante la fase de declive, estos casos están subrepresentados, lo que lleva a la estimación de intervalos de retraso más cortos y más largos, respectivamente (Park et al. en progreso).
3.2.2 Distribuciones de rezagos
Tres distribuciones de probabilidad comunes utilizadas para caracterizar rezagos en epidemiología de enfermedades infecciosas (Tabla 1):
| Distribución | Parámetros |
|---|---|
| Weibull |
shape y scale (forma y
escala) |
| gamma |
shape y scale (forma y
escala) |
| log normal |
log mean y
log standard deviation (media y desviación estándar
logarítmica) |
4. Paquetes de R para la practica
En esta practica se usarán los siguientes paquetes de
R:
dplyrpara manejo de datosepicontactspara visualizar los datos de rastreo de contactosggplot2ypatchworkpara gráficarincidencepara visualizar curvas epidemicasrstanpara estimar el período de incubacióncoarseDataToolsviaEpiEstimpara estimar el intervalo serial
Instrucciones de instalación para los paquetes:
Para cargar los paquetes, escriba:
R
library(dplyr)
library(epicontacts)
library(incidence)
library(coarseDataTools)
library(EpiEstim)
library(ggplot2)
library(loo)
library(patchwork)
library(rstan)
Para este taller, las autoras han creado algunas funciones que serán necesarias para el buen funcionamiento del mismo. Por favor, copie el siguiente texto, selecciónelo y ejecútelo para tener estas funciones en su ambiente global y poderlas utilizar.
R
## Calcule la verosimilitud DIC mediante integración
diclik <- function(par1, par2, EL, ER, SL, SR, dist){
## Si la ventana de síntomas es mayor que la ventana de exposición
if(SR-SL>ER-EL){
dic1 <- integrate(fw1, lower=SL-ER, upper=SL-EL,
subdivisions=10,
par1=par1, par2=par2,
EL=EL, ER=ER, SL=SL, SR=SR,
dist=dist)$value
if (dist == "W"){
dic2 <- (ER-EL)*
(pweibull(SR-ER, shape=par1, scale=par2) - pweibull(SL-EL, shape=par1, scale=par2))
} else if (dist == "off1W"){
dic2 <- (ER-EL)*
(pweibullOff1(SR-ER, shape=par1, scale=par2) - pweibullOff1(SL-EL, shape=par1, scale=par2))
} else if (dist == "G"){
dic2 <- (ER-EL)*
(pgamma(SR-ER, shape=par1, scale=par2) - pgamma(SL-EL, shape=par1, scale=par2))
} else if (dist == "off1G"){
dic2 <- (ER-EL)*
(pgammaOff1(SR-ER, shape=par1, scale=par2) - pgammaOff1(SL-EL, shape=par1, scale=par2))
} else if (dist == "L") {
dic2 <- (ER-EL)*
(plnorm(SR-ER, par1, par2) - plnorm(SL-EL, par1, par2))
} else if (dist == "off1L") {
dic2 <- (ER-EL)*
(plnormOff1(SR-ER, par1, par2) - plnormOff1(SL-EL, par1, par2))
} else {
stop("distribution not supported")
}
dic3 <- integrate(fw3, lower=SR-ER, upper=SR-EL,
subdivisions=10,
par1=par1, par2=par2,
EL=EL, ER=ER, SL=SL, SR=SR,
dist=dist)$value
return(dic1 + dic2 + dic3)
}
## Si la ventana de exposición es mayor que la ventana de síntomas
else{
dic1 <- integrate(fw1, lower=SL-ER, upper=SR-ER, subdivisions=10,
par1=par1, par2=par2,
EL=EL, ER=ER, SL=SL, SR=SR,
dist=dist)$value
if (dist == "W"){
dic2 <- (SR-SL)*
(pweibull(SL-EL, shape=par1, scale=par2) - pweibull(SR-ER, shape=par1, scale=par2))
} else if (dist == "off1W"){
dic2 <- (SR-SL)*
(pweibullOff1(SL-EL, shape=par1, scale=par2) - pweibullOff1(SR-ER, shape=par1, scale=par2))
} else if (dist == "G"){
dic2 <- (SR-SL)*
(pgamma(SL-EL, shape=par1, scale=par2) - pgamma(SR-ER, shape=par1, scale=par2))
} else if (dist == "off1G"){
dic2 <- (SR-SL)*
(pgammaOff1(SL-EL, shape=par1, scale=par2) - pgammaOff1(SR-ER, shape=par1, scale=par2))
} else if (dist == "L"){
dic2 <- (SR-SL)*
(plnorm(SL-EL, par1, par2) - plnorm(SR-ER, par1, par2))
} else if (dist == "off1L"){
dic2 <- (SR-SL)*
(plnormOff1(SL-EL, par1, par2) - plnormOff1(SR-ER, par1, par2))
} else {
stop("distribution not supported")
}
dic3 <- integrate(fw3, lower=SL-EL, upper=SR-EL,
subdivisions=10,
par1=par1, par2=par2,
EL=EL, ER=ER, SL=SL, SR=SR,
dist=dist)$value
return(dic1 + dic2 + dic3)
}
}
## Esta verosimilitud DIC está diseñada para datos que tienen intervalos superpuestos
diclik2 <- function(par1, par2, EL, ER, SL, SR, dist){
if(SL>ER) {
return(diclik(par1, par2, EL, ER, SL, SR, dist))
} else {
lik1 <- integrate(diclik2.helper1, lower=EL, upper=SL,
SL=SL, SR=SR, par1=par1, par2=par2, dist=dist)$value
lik2 <- integrate(diclik2.helper2, lower=SL, upper=ER,
SR=SR, par1=par1, par2=par2, dist=dist)$value
return(lik1+lik2)
}
}
## Funciones de verosimilitud para diclik2
diclik2.helper1 <- function(x, SL, SR, par1, par2, dist){
if (dist =="W"){
pweibull(SR-x, shape=par1, scale=par2) - pweibull(SL-x, shape=par1, scale=par2)
} else if (dist =="off1W") {
pweibullOff1(SR-x, shape=par1, scale=par2) - pweibullOff1(SL-x, shape=par1, scale=par2)
} else if (dist =="G") {
pgamma(SR-x, shape=par1, scale=par2) - pgamma(SL-x, shape=par1, scale=par2)
} else if (dist=="off1G"){
pgammaOff1(SR-x, shape=par1, scale=par2) - pgammaOff1(SL-x, shape=par1, scale=par2)
} else if (dist == "L"){
plnorm(SR-x, par1, par2) - plnorm(SL-x, par1, par2)
} else if (dist == "off1L"){
plnormOff1(SR-x, par1, par2) - plnormOff1(SL-x, par1, par2)
} else {
stop("distribution not supported")
}
}
diclik2.helper2 <- function(x, SR, par1, par2, dist){
if (dist =="W"){
pweibull(SR-x, shape=par1, scale=par2)
} else if (dist =="off1W") {
pweibullOff1(SR-x, shape=par1, scale=par2)
} else if (dist =="G") {
pgamma(SR-x, shape=par1, scale=par2)
} else if (dist =="off1G") {
pgammaOff1(SR-x, shape=par1, scale=par2)
} else if (dist=="L"){
plnorm(SR-x, par1, par2)
} else if (dist=="off1L"){
plnormOff1(SR-x, par1, par2)
} else {
stop("distribution not supported")
}
}
## Funciones que manipulan/calculan la verosimilitud para los datos censurados
## Las funciones codificadas aquí se toman directamente de las
## notas de verosimilitud censurada por intervalos dobles.
fw1 <- function(t, EL, ER, SL, SR, par1, par2, dist){
## Función que calcula la primera función para la integral DIC
if (dist=="W"){
(ER-SL+t) * dweibull(x=t,shape=par1,scale=par2)
} else if (dist=="off1W") {
(ER-SL+t) * dweibullOff1(x=t,shape=par1,scale=par2)
} else if (dist=="G") {
(ER-SL+t) * dgamma(x=t, shape=par1, scale=par2)
} else if (dist=="off1G") {
(ER-SL+t) * dgammaOff1(x=t, shape=par1, scale=par2)
} else if (dist =="L"){
(ER-SL+t) * dlnorm(x=t, meanlog=par1, sdlog=par2)
} else if (dist =="off1L"){
(ER-SL+t) * dlnormOff1(x=t, meanlog=par1, sdlog=par2)
} else {
stop("distribution not supported")
}
}
fw3 <- function(t, EL, ER, SL, SR, par1, par2, dist){
## Función que calcula la tercera función para la integral DIC
if (dist == "W"){
(SR-EL-t) * dweibull(x=t, shape=par1, scale=par2)
} else if (dist == "off1W"){
(SR-EL-t) * dweibullOff1(x=t, shape=par1, scale=par2)
} else if (dist == "G"){
(SR-EL-t) * dgamma(x=t, shape=par1, scale=par2)
} else if (dist == "off1G"){
(SR-EL-t) * dgammaOff1(x=t, shape=par1, scale=par2)
} else if (dist == "L") {
(SR-EL-t) * dlnorm(x=t, meanlog=par1, sdlog=par2)
} else if (dist == "off1L"){
(SR-EL-t) * dlnormOff1(x=t, meanlog=par1, sdlog=par2)
} else {
stop("distribution not supported")
}
}
5. Datos
Esta práctica está partida en dos grupos para abordar dos enfermedades desconocidas con diferentes modos de transmisión.
Cargue los datos simulados que están guardados como un archivo .RDS, de acuerdo a su grupo asignado. Puede encontrar esta información en la carpeta Enfermedad X. Descargue la carpeta, extráigala en el computador y abra el proyecto de R.
Hay dos elementos de interés:
linelist, un archivo que contiene una lista de casos de la Enfermedad X, un caso por fila.contacts, un archivo con datos de rastreo de contactos que contiene información sobre pares de casos primarios y secundarios.
R
# Grupo 1
dat <- readRDS("data/practical_data_group1.RDS")
linelist <- dat$linelist
contacts <- dat$contacts
6. Exploración de los datos
6.1. Exploración de los datos en
linelist
Empiece con linelist. Estos datos fueron recolectados
como parte de la vigilancia epidemiológica rutinaria. Cada fila
representa un caso de la Enfermedad X, y hay 7 variables:
id: número único de identificación del casodate_onset: fecha de inicio de los síntomas del pacientesex: : M = masculino; F = femeninoage: edad del paciente en añosexposure: información sobre cómo el paciente podría haber estado expuestoexposure_start: primera fecha en que el paciente estuvo expuestoexposure_end: última fecha en que el paciente estuvo expuesto
💡 Preguntas (1)
¿Cuántos casos hay en los datos de
linelist?¿Qué proporción de los casos son femeninos?
¿Cuál es la distribución de edades de los casos?
¿Qué tipo de información sobre la exposición está disponible?
R
# Inspecionar los datos
head(linelist)
SALIDA
id date_onset sex age exposure exposure_start exposure_end
1 1 2023-10-01 M 34 Close, skin-to-skin contact <NA> <NA>
2 2 2023-10-03 F 38 Close, skin-to-skin contact 2023-09-29 2023-09-29
3 3 2023-10-06 F 38 Close, skin-to-skin contact 2023-09-28 2023-09-28
4 4 2023-10-10 F 37 <NA> 2023-09-25 2023-09-27
5 5 2023-10-11 F 33 <NA> 2023-10-05 2023-10-05
6 6 2023-10-12 F 34 Close, skin-to-skin contact 2023-10-10 2023-10-10R
# P1
nrow(linelist)
SALIDA
[1] 166R
# P2
table(linelist$sex)[2]/nrow(linelist)
SALIDA
M
0.6144578 R
# P3
summary(linelist$age)
SALIDA
Min. 1st Qu. Median Mean 3rd Qu. Max.
22.00 33.00 36.00 35.51 38.00 47.00 R
# P4
table(linelist$exposure, exclude = F)[1]/nrow(linelist)
SALIDA
Close, skin-to-skin contact
0.6626506 💡 Discusión
¿Por qué cree que falta la información de exposición en algunos casos?
Ahora, grafique la curva epidémica. ¿En qué parte del brote cree que está (principio, medio, final)?
R
i <- incidence(linelist$date_onset)
plot(i) +
theme_classic() +
scale_fill_manual(values = "purple") +
theme(legend.position = "none")
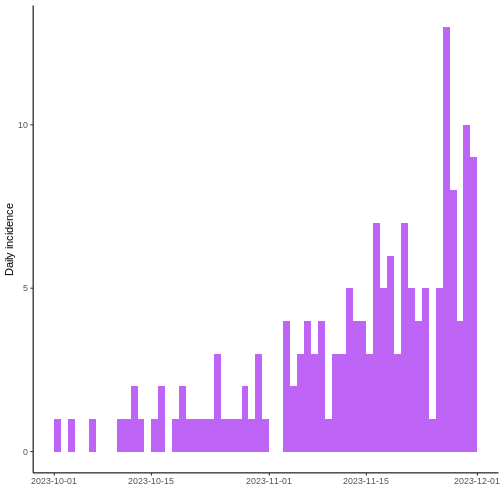
Parece que la epidemia todavía podría esta creciendo.
6.2. Exploración de los datos de
rastreo de contactos
Ahora vea los datos de rastreo de contactos, que se obtuvieron a través de entrevistas a los pacientes. A los pacientes se les preguntó sobre actividades e interacciones recientes para identificar posibles fuentes de infección. Se emparejaron pares de casos primarios y secundarios si el caso secundario nombraba al caso primario como un contacto. Solo hay información de un subconjunto de los casos porque no todos los pacientes pudieron ser contactados para una entrevista.
Note que para este ejercicio, se asumirá que los casos secundarios solo tenían un posible infectante. En realidad, la posibilidad de que un caso tenga múltiples posibles infectantes necesita ser evaluada.
Los datos de rastreo de contactos tienen 4 variables:
primary_case_id: número de identificación único para el caso primario (infectante)secondary_case_id: número de identificación único para el caso secundario (infectado)primary_onset_date: fecha de inicio de síntomas del caso primariosecondary_onset_date: fecha de inicio de síntomas del caso secundario
R
x <- make_epicontacts(linelist = linelist,
contacts = contacts,
from = "primary_case_id",
to = "secondary_case_id",
directed = TRUE) # Esto indica que los contactos son directos (i.e., este gráfico traza una flecha desde los casos primarios a los secundarios)
plot(x)
💡 Preguntas (2)
- Describa los grupos (clusters).
- ¿Ve algún evento potencial de superpropagación (donde un caso propaga el patógeno a muchos otros casos)?
_______Pausa 1 _________
7. Estimación del período de incubación
Ahora, enfoquese en el período de incubación. Se utilizará los datos
del linelist para esta parte. Se necesitan ambos el tiempo
de inicio de sintomas y el timpo de la posible exposición. Note que en
los datos hay dos fechas de exposición, una de inicio y una de final.
Algunas veces la fecha exacta de exposición es desconocida y en su lugar
se obtiene la ventana de exposición durante la entrevista.
💡 Preguntas (3)
¿Para cuántos casos tiene datos tanto de la fecha de inicio de síntomas como de exposición?
Calcule las ventanas de exposición. ¿Cuántos casos tienen una única fecha de exposición?
R
ip <- filter(linelist, !is.na(exposure_start) &
!is.na(exposure_end))
nrow(ip)
SALIDA
[1] 50R
ip$exposure_window <- as.numeric(ip$exposure_end - ip$exposure_start)
table(ip$exposure_window)
SALIDA
0 1 2
34 11 5 7.1. Estimación naive del período de incubación
Empiece calculando una estimación naive del período de incubación.
R
# Máximo tiempo de período de incubación
ip$max_ip <- ip$date_onset - ip$exposure_start
summary(as.numeric(ip$max_ip))
SALIDA
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 3.00 4.50 6.38 7.75 20.00 R
# Mínimo tiempo de período de incubación
ip$min_ip <- ip$date_onset - ip$exposure_end
summary(as.numeric(ip$min_ip))
SALIDA
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 2.00 4.00 5.96 7.75 19.00 7.2. Censura estimada ajustada del período de incubación
Ahora, ajuste tres distribuciones de probabilidad a los datos del
período de incubación teniendo en cuenta la censura doble. Adapte un
código de stan que fue publicado por Miura et al. durante
el brote global de mpox de 2022. Este método no tiene en cuenta el
truncamiento a la derecha ni el sesgo dinámico.
Recuerde que el interés principal es considerar tres distribuciones de probabilidad: Weibull, gamma y log normal (Ver Tabla 1).
Stan es un programa de software que implementa el
algoritmo Monte Carlo Hamiltoniano (HMC por su siglas en inglés de
Hamiltonian Monte Carlo). HMC es un método de Monte Carlo de cadena de
Markov (MCMC) para ajustar modelos complejos a datos utilizando
estadísticas bayesianas.
7.1.1. Corra el modelo en Stan
Ajuste las tres distribuciones en este bloque de código.
R
# Prepare los datos
earliest_exposure <- as.Date(min(ip$exposure_start))
ip <- ip |>
mutate(date_onset = as.numeric(date_onset - earliest_exposure),
exposure_start = as.numeric(exposure_start - earliest_exposure),
exposure_end = as.numeric(exposure_end - earliest_exposure)) |>
select(id, date_onset, exposure_start, exposure_end)
# Configure algunas opciones para ejecutar las cadenas MCMC en paralelo
# Ejecución de las cadenas MCMC en paralelo significa que se ejecutaran varias cadenas al mismo tiempo usando varios núcleos de su computador
options(mc.cores=parallel::detectCores())
input_data <- list(N = length(ip$exposure_start), # NNúmero de observaciones
tStartExposure = ip$exposure_start,
tEndExposure = ip$exposure_end,
tSymptomOnset = ip$date_onset)
# tres distribuciones de probabilidad
distributions <- c("weibull", "gamma", "lognormal")
# Código de Stan
code <- sprintf("
data{
int<lower=1> N;
vector[N] tStartExposure;
vector[N] tEndExposure;
vector[N] tSymptomOnset;
}
parameters{
real<lower=0> par[2];
vector<lower=0, upper=1>[N] uE; // Uniform value for sampling between start and end exposure
}
transformed parameters{
vector[N] tE; // infection moment
tE = tStartExposure + uE .* (tEndExposure - tStartExposure);
}
model{
// Contribution to likelihood of incubation period
target += %s_lpdf(tSymptomOnset - tE | par[1], par[2]);
}
generated quantities {
// likelihood for calculation of looIC
vector[N] log_lik;
for (i in 1:N) {
log_lik[i] = %s_lpdf(tSymptomOnset[i] - tE[i] | par[1], par[2]);
}
}
", distributions, distributions)
names(code) <- distributions
# La siguiente línea puede tomar ~1.5 min
models <- mapply(stan_model, model_code = code)
# Toma ~40 sec.
fit <- mapply(sampling, models, list(input_data),
iter=3000, # Número de iteraciones (largo de la cadena MCMC)
warmup=1000, # Número de muestras a descartar al inicio de MCMC
chain=4) # Número de cadenas MCMC a ejecutar
SALIDA
0.81 seconds (Total)
Chain 3: R
pos <- mapply(function(z) rstan::extract(z)$par, fit, SIMPLIFY=FALSE) # muestreo posterior
7.1.2. Revisar si hay convergencia
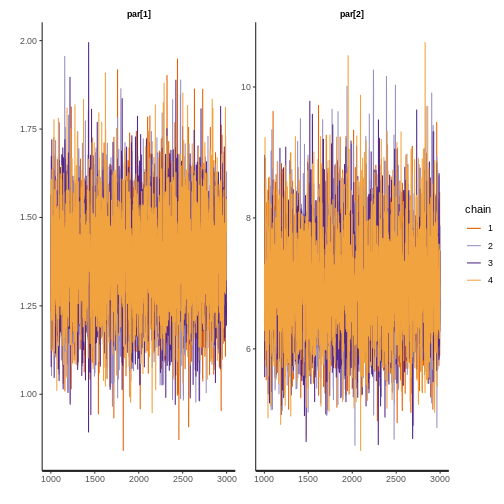
Ahora verifique la convergencia del modelo. Observe los valores de r-hat, los tamaños de muestra efectivos y las trazas MCMC. R-hat compara las estimaciones entre y dentro de cadenas para los parámetros del modelo; valores cercanos a 1 indican que las cadenas se han mezclado bien (Vehtari et al. 2021). El tamaño de muestra efectivo estima el número de muestras independientes después de tener en cuenta la dependencia en las cadenas MCMC (Lambert 2018). Para un modelo con 4 cadenas MCMC, se recomienda un tamaño total de muestra efectiva de al menos 400 (Vehtari et al. 2021).
Para cada modelo con distribución ajustada:
💡 Preguntas (4)
¿Los valores de r-hat son cercanos a 1?
¿Las 4 cadenas MCMC generalmente se superponen y permanecen alrededor de los mismos valores (se ven como orugas peludas)?
7.1.2.1. Convergencia para Gamma
R
print(fit$gamma, digits = 3, pars = c("par[1]","par[2]"))
SALIDA
Inference for Stan model: anon_model.
4 chains, each with iter=3000; warmup=1000; thin=1;
post-warmup draws per chain=2000, total post-warmup draws=8000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
par[1] 1.983 0.003 0.354 1.343 1.739 1.960 2.204 2.748 12219 1
par[2] 0.326 0.001 0.066 0.209 0.280 0.321 0.367 0.466 11250 1
Samples were drawn using NUTS(diag_e) at Tue Apr 28 03:04:25 2026.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).R
rstan::traceplot(fit$gamma, pars = c("par[1]","par[2]"))
7.1.2.2. Convergencia para log normal
R
print(fit$lognormal, digits = 3, pars = c("par[1]","par[2]"))
SALIDA
Inference for Stan model: anon_model.
4 chains, each with iter=3000; warmup=1000; thin=1;
post-warmup draws per chain=2000, total post-warmup draws=8000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
par[1] 1.529 0.001 0.117 1.301 1.451 1.531 1.603 1.760 9577 1
par[2] 0.801 0.001 0.083 0.657 0.741 0.795 0.852 0.981 8891 1
Samples were drawn using NUTS(diag_e) at Tue Apr 28 03:04:35 2026.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).R
rstan::traceplot(fit$lognormal, pars = c("par[1]","par[2]"))
7.1.2.3. Convergencia para Weibull
R
print(fit$weibull, digits = 3, pars = c("par[1]","par[2]"))
SALIDA
Inference for Stan model: anon_model.
4 chains, each with iter=3000; warmup=1000; thin=1;
post-warmup draws per chain=2000, total post-warmup draws=8000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
par[1] 1.374 0.001 0.147 1.101 1.271 1.368 1.470 1.678 9952 1
par[2] 6.965 0.008 0.783 5.545 6.414 6.932 7.461 8.593 9230 1
Samples were drawn using NUTS(diag_e) at Tue Apr 28 03:04:14 2026.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).R
rstan::traceplot(fit$weibull, pars = c("par[1]","par[2]"))
7.1.3. Calcule los criterios de comparación de los modelos
Calcule el criterio de información ampliamente aplicable (WAIC) y el criterio de información de dejar-uno-fuera (LOOIC) para comparar los ajustes de los modelos. El modelo con mejor ajuste es aquel con el WAIC o LOOIC más bajo. En esta sección también se resumirá las distribuciones y se hará algunos gráficos.
💡 Preguntas (5)
- ¿Qué modelo tiene mejor ajuste?
R
# Calcule WAIC para los tres modelos
waic <- mapply(function(z) waic(extract_log_lik(z))$estimates[3,], fit)
waic
SALIDA
weibull gamma lognormal
Estimate 278.14667 276.09357 272.84314
SE 11.93824 13.45744 13.86952R
# Para looic, se necesita proveer los tamaños de muestra relativos
# al llamar a loo. Este paso lleva a mejores estimados de los tamaños de
# muestra PSIS efectivos y del error de Monte Carlo
# Extraer la verosimilitud puntual logarítmica para la distribución Weibull
loglik <- extract_log_lik(fit$weibull, merge_chains = FALSE)
# Obtener los tamaños de muestra relativos efectivos
r_eff <- relative_eff(exp(loglik), cores = 2)
# Calcula LOOIC
loo_w <- loo(loglik, r_eff = r_eff, cores = 2)$estimates[3,]
# Imprimir los resultados
loo_w[1]
SALIDA
Estimate
278.1793 R
# Extraer la verosimilitud puntual logarítmica para la distribución gamma
loglik <- extract_log_lik(fit$gamma, merge_chains = FALSE)
r_eff <- relative_eff(exp(loglik), cores = 2)
loo_g <- loo(loglik, r_eff = r_eff, cores = 2)$estimates[3,]
loo_g[1]
SALIDA
Estimate
276.1107 R
# Extraer la verosimilitud puntual logarítmica para la distribución log normal
loglik <- extract_log_lik(fit$lognormal, merge_chains = FALSE)
r_eff <- relative_eff(exp(loglik), cores = 2)
loo_l <- loo(loglik, r_eff = r_eff, cores = 2)$estimates[3,]
loo_l[1]
SALIDA
Estimate
272.8553 7.1.4. Reporte los resultados
La cola derecha de la distribución del período de incubación es importante para diseñar estrategias de control (por ejemplo, cuarentena), los percentiles del 25 al 75 informan sobre el momento más probable en que podría ocurrir la aparición de síntomas, y la distribución completa puede usarse como una entrada en modelos matemáticos o estadísticos, como para pronósticos (Lessler et al. 2009).
Obtenga las estadísticas resumidas.
R
# Necesitamos convertir los parámetros de las distribuciones a la media y desviación estándar del rezago
# En Stan, los parámetros de las distribuciones son:
# Weibull: forma y escala
# Gamma: forma e inversa de la escala (aka rate)
# Log Normal: mu y sigma
# Referencia: https://mc-stan.org/docs/2_21/functions-reference/positive-continuous-distributions.html
# Calcule las medias
means <- cbind(
pos$weibull[, 2] * gamma(1 + 1 / pos$weibull[, 1]), # media de Weibull
pos$gamma[, 1] / pos$gamma[, 2], # media de gamma
exp(pos$lognormal[, 1] + pos$lognormal[, 2]^2 / 2) # media de log normal
)
# Calcule las desviaciones estándar
standard_deviations <- cbind(
sqrt(pos$weibull[, 2]^2 * (gamma(1 + 2 / pos$weibull[, 1]) - (gamma(1 + 1 / pos$weibull[, 1]))^2)),
sqrt(pos$gamma[, 1] / (pos$gamma[, 2]^2)),
sqrt((exp(pos$lognormal[, 2]^2) - 1) * (exp(2 * pos$lognormal[, 1] + pos$lognormal[, 2]^2)))
)
# Imprimir los rezagos medios e intervalos creíbles del 95%
probs <- c(0.025, 0.5, 0.975)
res_means <- apply(means, 2, quantile, probs)
colnames(res_means) <- colnames(waic)
res_means
SALIDA
weibull gamma lognormal
2.5% 5.162944 5.047521 5.011703
50% 6.350201 6.105813 6.325099
97.5% 7.852847 7.551731 8.568739R
res_sds <- apply(standard_deviations, 2, quantile, probs)
colnames(res_sds) <- colnames(waic)
res_sds
SALIDA
weibull gamma lognormal
2.5% 3.702682 3.432961 3.983202
50% 4.657309 4.352600 5.928212
97.5% 6.378350 5.793957 10.138079R
# Informe la mediana e intervalos creíbles del 95% para los cuantiles de cada distribución
quantiles_to_report <- c(0.025, 0.05, 0.5, 0.95, 0.975, 0.99)
# Weibull
cens_w_percentiles <- sapply(quantiles_to_report, function(p) quantile(qweibull(p = p, shape = pos$weibull[,1], scale = pos$weibull[,2]), probs = probs))
colnames(cens_w_percentiles) <- quantiles_to_report
print(cens_w_percentiles)
SALIDA
0.025 0.05 0.5 0.95 0.975 0.99
2.5% 0.2218029 0.4207363 4.110995 12.55571 14.47337 16.76505
50% 0.4716734 0.7901334 5.299369 15.38876 17.90371 21.04740
97.5% 0.8488524 1.3046082 6.696345 20.14517 24.02002 29.02643R
# Gamma
cens_g_percentiles <- sapply(quantiles_to_report, function(p) quantile(qgamma(p = p, shape = pos$gamma[,1], rate = pos$gamma[,2]), probs = probs))
colnames(cens_g_percentiles) <- quantiles_to_report
print(cens_g_percentiles)
SALIDA
0.025 0.05 0.5 0.95 0.975 0.99
2.5% 0.3371592 0.5732772 4.116533 11.86453 13.79674 16.30634
50% 0.7159084 1.0566041 5.099839 14.54302 17.13034 20.43005
97.5% 1.1823128 1.6111619 6.312610 18.71430 22.27903 26.94720R
# Log normal
cens_ln_percentiles <- sapply(quantiles_to_report, function(p) quantile(qlnorm(p = p, meanlog = pos$lognormal[,1], sdlog= pos$lognormal[,2]), probs = probs))
colnames(cens_ln_percentiles) <- quantiles_to_report
print(cens_ln_percentiles)
SALIDA
0.025 0.05 0.5 0.95 0.975 0.99
2.5% 0.6308007 0.846627 3.672551 12.55924 15.59312 20.04685
50% 0.9755542 1.252638 4.620757 17.03591 21.86243 29.24269
97.5% 1.3581149 1.692592 5.810738 25.50117 34.20586 48.61585Para cada modelo, encuentre estos elementos para el período de incubación estimado en la salida de arriba y escribalos abajo.
Media e intervalo de credibilidad del 95%
Desviación estándar e intervalo de credibilidad del 95%
Percentiles (e.g., 2.5, 5, 25, 50, 75, 95, 97.5, 99)
Los parámetros de las distribuciones ajustadas (e.g., shape y scale para distribución gamma)
7.1.5. Grafique los resultados
R
# Prepare los resultados para graficarlos
df <- data.frame(
#Tome los valores de las medias para trazar la función de densidad acumulatica empirica
inc_day = ((input_data$tSymptomOnset-input_data$tEndExposure)+(input_data$tSymptomOnset-input_data$tStartExposure))/2
)
x_plot <- seq(0, 30, by=0.1) # Esto configura el rango del eje x (número de días)
Gam_plot <- as.data.frame(list(dose= x_plot,
pred= sapply(x_plot, function(q) quantile(pgamma(q = q, shape = pos$gamma[,1], rate = pos$gamma[,2]), probs = c(0.5))),
low = sapply(x_plot, function(q) quantile(pgamma(q = q, shape = pos$gamma[,1], rate = pos$gamma[,2]), probs = c(0.025))),
upp = sapply(x_plot, function(q) quantile(pgamma(q = q, shape = pos$gamma[,1], rate = pos$gamma[,2]), probs = c(0.975)))
))
Wei_plot <- as.data.frame(list(dose= x_plot,
pred= sapply(x_plot, function(q) quantile(pweibull(q = q, shape = pos$weibull[,1], scale = pos$weibull[,2]), probs = c(0.5))),
low = sapply(x_plot, function(q) quantile(pweibull(q = q, shape = pos$weibull[,1], scale = pos$weibull[,2]), probs = c(0.025))),
upp = sapply(x_plot, function(q) quantile(pweibull(q = q, shape = pos$weibull[,1], scale = pos$weibull[,2]), probs = c(0.975)))
))
ln_plot <- as.data.frame(list(dose= x_plot,
pred= sapply(x_plot, function(q) quantile(plnorm(q = q, meanlog = pos$lognormal[,1], sdlog= pos$lognormal[,2]), probs = c(0.5))),
low = sapply(x_plot, function(q) quantile(plnorm(q = q, meanlog = pos$lognormal[,1], sdlog= pos$lognormal[,2]), probs = c(0.025))),
upp = sapply(x_plot, function(q) quantile(plnorm(q = q, meanlog = pos$lognormal[,1], sdlog= pos$lognormal[,2]), probs = c(0.975)))
))
# Grafique las curvas de la distribución acumulada
gamma_ggplot <- ggplot(df, aes(x=inc_day)) +
stat_ecdf(geom = "step")+
xlim(c(0, 30))+
geom_line(data=Gam_plot, aes(x=x_plot, y=pred), color=RColorBrewer::brewer.pal(11, "RdBu")[11], linewidth=1) +
geom_ribbon(data=Gam_plot, aes(x=x_plot,ymin=low,ymax=upp), fill = RColorBrewer::brewer.pal(11, "RdBu")[11], alpha=0.1) +
theme_bw(base_size = 11)+
labs(x="Incubation period (days)", y = "Proportion")+
ggtitle("Gamma")
weibul_ggplot <- ggplot(df, aes(x=inc_day)) +
stat_ecdf(geom = "step")+
xlim(c(0, 30))+
geom_line(data=Wei_plot, aes(x=x_plot, y=pred), color=RColorBrewer::brewer.pal(11, "RdBu")[11], linewidth=1) +
geom_ribbon(data=Wei_plot, aes(x=x_plot,ymin=low,ymax=upp), fill = RColorBrewer::brewer.pal(11, "RdBu")[11], alpha=0.1) +
theme_bw(base_size = 11)+
labs(x="Incubation period (days)", y = "Proportion")+
ggtitle("Weibull")
lognorm_ggplot <- ggplot(df, aes(x=inc_day)) +
stat_ecdf(geom = "step")+
xlim(c(0, 30))+
geom_line(data=ln_plot, aes(x=x_plot, y=pred), color=RColorBrewer::brewer.pal(11, "RdBu")[11], linewidth=1) +
geom_ribbon(data=ln_plot, aes(x=x_plot,ymin=low,ymax=upp), fill = RColorBrewer::brewer.pal(11, "RdBu")[11], alpha=0.1) +
theme_bw(base_size = 11)+
labs(x="Incubation period (days)", y = "Proportion")+
ggtitle("Log normal")
(lognorm_ggplot|gamma_ggplot|weibul_ggplot) + plot_annotation(tag_levels = 'A')
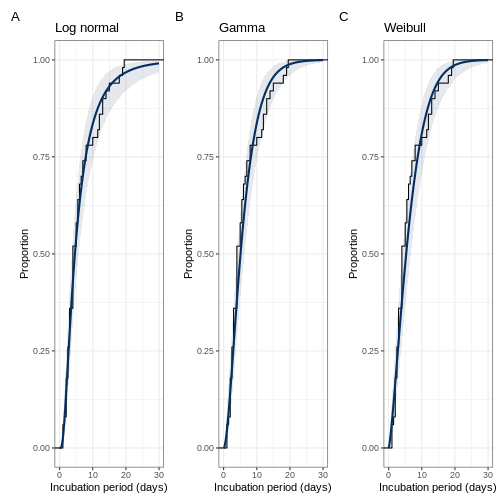
En los gráficos anteriores, la línea negra es la distribución acumulativa empírica (los datos), mientras que la curva azul es la distribución de probabilidad ajustada con los intervalos de credibilidad del 95%. Asegúrese de que la curva azul esté sobre la línea negra.
💡 Preguntas (6)
- ¿Son los ajustes de las distribuciones lo que espera?
_______Pausa 2 _________
8. Estimación del intervalo serial
Ahora, estime el intervalo serial. Nuevamente, se realizará primero una estimación navie calculando la diferencia entre la fecha de inicio de síntomas entre el par de casos primario y secundario.
¿Existen casos con intervalos seriales negativos en los datos (por ejemplo, el inicio de los síntomas en el caso secundario ocurrió antes del inicio de los síntomas en el caso primario)?
Informe la mediana del intervalo serial, así como el mínimo y el máximo.
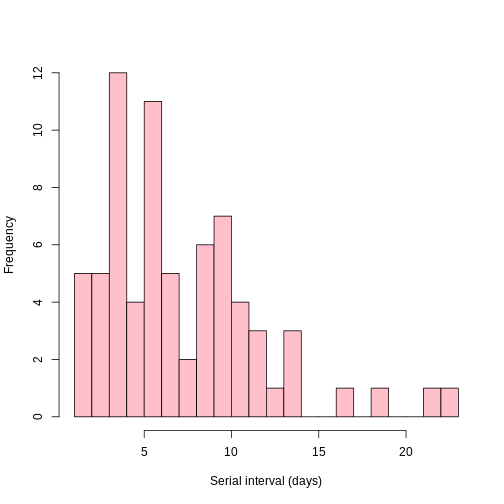
Grafique la distribución del intervalo serial.
8.1. Estimación naive
R
contacts$diff <- as.numeric(contacts$secondary_onset_date - contacts$primary_onset_date)
summary(contacts$diff)
SALIDA
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 4.000 6.000 7.625 10.000 23.000 R
hist(contacts$diff, xlab = "Serial interval (days)", breaks = 25, main = "", col = "pink")
8.2. Estimación ajustada por censura
Ahora se estimará el intervalo serial utilizando una implementación
del paquete courseDataTools dentro del paquete R
EpiEstim. Este método tiene en cuenta la censura doble y
permite comparar diferentes distribuciones de probabilidad, pero no se
ajusta por truncamiento a la derecha o sesgo dinámico.
Se considerará tres distribuciones de probabilidad y deberá seleccionar la que mejor se ajuste a los datos utilizando WAIC o LOOIC. Recuerde que la distribución con mejor ajuste tendrá el WAIC o LOOIC más bajo.
Ten en cuenta que en coarseDataTools, los parámetros
para las distribuciones son ligeramente diferentes que en rstan. Aquí,
los parámetros para la distribución gamma son shape y scale (forma y
escala) (https://cran.r-project.org/web/packages/coarseDataTools/coarseDataTools.pdf).
Solo se ejecutará una cadena MCMC para cada distribución en interés del tiempo, pero en la práctica debería ejecutar más de una cadena para asegurarse de que el MCMC converge en la distribución objetivo. Usará las distribuciones a priori predeterminadas, que se pueden encontrar en la documentación del paquete (ver ‘detalles’ para la función dic.fit.mcmc aquí: (https://cran.r-project.org/web/packages/coarseDataTools/coarseDataTools.pdf).
8.2.1. Preparación de los datos
R
# Formatee los datos de intervalos censurados del intervalo serial
# Cada línea representa un evento de transmisión
# EL/ER muestran el límite inferior/superior de la fecha de inicio de los síntomas en el caso primario (infector)
# SL/SR muestran lo mismo para el caso secundario (infectado)
# type tiene entradas 0 que corresponden a datos censurados doblemente por intervalo
# (ver Reich et al. Statist. Med. 2009)
si_data <- contacts |>
select(-primary_case_id, -secondary_case_id, -primary_onset_date, -secondary_onset_date,) |>
rename(SL = diff) |>
mutate(type = 0, EL = 0, ER = 1, SR = SL + 1) |>
select(EL, ER, SL, SR, type)
8.2.2. Ajuste una distribución gamma para el SI
Primero, ajuste una distribución gamma al intervalo serial.
R
overall_seed <- 3 # semilla para el generador de números aleatorios para MCMC
MCMC_seed <- 007
# Ejecutaremos el modelo durante 4000 iteraciones con las primeras 1000 muestras descartadas como burning
n_mcmc_samples <- 3000 # número de muestras a extraer de la posterior (después del burning)
params = list(
dist = "G", # Ajuste de una distribución Gamma para el Intervalo Serial (SI)
method = "MCMC", # MCMC usando coarsedatatools
burnin = 1000, # número de muestras de burning (muestras descartadas al comienzo de MCMC)
n1 = 50, # n1 es el número de pares de media y desviación estándar del SI que se extraen
n2 = 50) # n2 es el tamaño de la muestra posterior extraída para cada par de media y desviación estándar del SI
mcmc_control <- make_mcmc_control(
seed = MCMC_seed,
burnin = params$burnin)
dist <- params$dist
config <- make_config(
list(
si_parametric_distr = dist,
mcmc_control = mcmc_control,
seed = overall_seed,
n1 = params$n1,
n2 = params$n2))
# Ajuste el SI
si_fit_gamma <- coarseDataTools::dic.fit.mcmc(
dat = si_data,
dist = dist,
init.pars = init_mcmc_params(si_data, dist),
burnin = mcmc_control$burnin,
n.samples = n_mcmc_samples,
seed = mcmc_control$seed)
SALIDA
Running 4000 MCMC iterations
MCMCmetrop1R iteration 1 of 4000
function value = -201.95281
theta =
1.04012
0.99131
Metropolis acceptance rate = 0.00000
MCMCmetrop1R iteration 1001 of 4000
function value = -202.42902
theta =
0.95294
1.05017
Metropolis acceptance rate = 0.55445
MCMCmetrop1R iteration 2001 of 4000
function value = -201.88547
theta =
1.18355
0.82124
Metropolis acceptance rate = 0.56522
MCMCmetrop1R iteration 3001 of 4000
function value = -202.11109
theta =
1.26323
0.77290
Metropolis acceptance rate = 0.55148
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
The Metropolis acceptance rate was 0.55500
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@Ahora observe los resultados.
R
# Verificar convergencia de las cadenas MCMC
converg_diag_gamma <- check_cdt_samples_convergence(si_fit_gamma@samples)
SALIDA
Gelman-Rubin MCMC convergence diagnostic was successful.R
converg_diag_gamma
SALIDA
[1] TRUER
# Guardar las muestras MCMC en un dataframe
si_samples_gamma <- data.frame(
type = 'Symptom onset',
shape = si_fit_gamma@samples$var1,
scale = si_fit_gamma@samples$var2,
p50 = qgamma(
p = 0.5,
shape = si_fit_gamma@samples$var1,
scale = si_fit_gamma@samples$var2)) |>
mutate( # La ecuación de conversión se encuentra aquí: https://en.wikipedia.org/wiki/Gamma_distribution
mean = shape*scale,
sd = sqrt(shape*scale^2)
)
# Obtener la media, desviación estándar y 95% CrI
si_summary_gamma <-
si_samples_gamma %>%
summarise(
mean_mean = quantile(mean,probs=.5),
mean_l_ci = quantile(mean,probs=.025),
mean_u_ci = quantile(mean,probs=.975),
sd_mean = quantile(sd, probs=.5),
sd_l_ci = quantile(sd,probs=.025),
sd_u_ci = quantile(sd,probs=.975)
)
si_summary_gamma
SALIDA
mean_mean mean_l_ci mean_u_ci sd_mean sd_l_ci sd_u_ci
1 7.659641 6.65395 8.707372 4.342087 3.602425 5.481316R
# Obtenga las mismas estadísticas de resumen para los parámetros de la distribución
si_samples_gamma |>
summarise(
shape_mean = quantile(shape, probs=.5),
shape_l_ci = quantile(shape, probs=.025),
shape_u_ci = quantile(shape, probs=.975),
scale_mean = quantile(scale, probs=.5),
scale_l_ci = quantile(scale, probs=.025),
scale_u_ci = quantile(scale, probs=.975)
)
R
# Necesita esto para hacer gráficos más tarde
gamma_shape <- si_fit_gamma@ests['shape',][1]
gamma_rate <- 1 / si_fit_gamma@ests['scale',][1]
8.2.3. Ajuste de una distribución log normal para el intervalo serial
Ahora, ajuste una distribución log normal a los datos del intervalo serial.
R
# Ejecute el modelo durante 4000 iteraciones, descartando las primeras 1000 muestras como burning
n_mcmc_samples <- 3000 # número de muestras a extraer de la posterior (después del burning)
params = list(
dist = "L", # Ajustando una distribución log-normal para el Intervalo Serial (SI)
method = "MCMC", # MCMC usando coarsedatatools
burnin = 1000, # número de muestras de burning (muestras descartadas al comienzo de MCMC)
n1 = 50, # n1 es el número de pares de media y desviación estándar de SI que se extraen
n2 = 50) # n2 es el tamaño de la muestra posterior extraída para cada par de media y desviación estándar de SI
mcmc_control <- make_mcmc_control(
seed = MCMC_seed,
burnin = params$burnin)
dist <- params$dist
config <- make_config(
list(
si_parametric_distr = dist,
mcmc_control = mcmc_control,
seed = overall_seed,
n1 = params$n1,
n2 = params$n2))
# Ajuste del intervalo serial
si_fit_lnorm <- coarseDataTools::dic.fit.mcmc(
dat = si_data,
dist = dist,
init.pars = init_mcmc_params(si_data, dist),
burnin = mcmc_control$burnin,
n.samples = n_mcmc_samples,
seed = mcmc_control$seed)
SALIDA
Running 4000 MCMC iterations
MCMCmetrop1R iteration 1 of 4000
function value = -216.54581
theta =
1.94255
-0.47988
Metropolis acceptance rate = 1.00000
MCMCmetrop1R iteration 1001 of 4000
function value = -216.21549
theta =
1.81272
-0.47418
Metropolis acceptance rate = 0.56643
MCMCmetrop1R iteration 2001 of 4000
function value = -215.86791
theta =
1.85433
-0.52118
Metropolis acceptance rate = 0.57221
MCMCmetrop1R iteration 3001 of 4000
function value = -216.32347
theta =
1.93196
-0.52205
Metropolis acceptance rate = 0.55948
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
The Metropolis acceptance rate was 0.56875
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@Revise los resultados.
R
# Revise la convergencia de las cadenas MCMC
converg_diag_lnorm <- check_cdt_samples_convergence(si_fit_lnorm@samples)
SALIDA
Gelman-Rubin MCMC convergence diagnostic was successful.R
converg_diag_lnorm
SALIDA
[1] TRUER
# Guarde las muestras de MCMC en un dataframe
si_samples_lnorm <- data.frame(
type = 'Symptom onset',
meanlog = si_fit_lnorm@samples$var1,
sdlog = si_fit_lnorm@samples$var2,
p50 = qlnorm(
p = 0.5,
meanlog = si_fit_lnorm@samples$var1,
sdlog = si_fit_lnorm@samples$var2)) |>
mutate( # La ecuación para la conversión está aquí https://en.wikipedia.org/wiki/Log-normal_distribution
mean = exp(meanlog + (sdlog^2/2)),
sd = sqrt((exp(sdlog^2)-1) * (exp(2*meanlog + sdlog^2)))
)
R
# Obtenga la media, desviación estándar e intervalo de credibilidad del 95%
si_summary_lnorm <-
si_samples_lnorm %>%
summarise(
mean_mean = quantile(mean,probs=.5),
mean_l_ci = quantile(mean,probs=.025),
mean_u_ci = quantile(mean,probs=.975),
sd_mean = quantile(sd, probs=.5),
sd_l_ci = quantile(sd,probs=.025),
sd_u_ci = quantile(sd,probs=.975)
)
si_summary_lnorm
SALIDA
mean_mean mean_l_ci mean_u_ci sd_mean sd_l_ci sd_u_ci
1 7.780719 6.692829 9.300588 5.189349 3.936678 7.289224R
# Obtenga las estadísticas resumen para los parámetros de la distribución
si_samples_lnorm |>
summarise(
meanlog_mean = quantile(meanlog, probs=.5),
meanlog_l_ci = quantile(meanlog, probs=.025),
meanlog_u_ci = quantile(meanlog, probs=.975),
sdlog_mean = quantile(sdlog, probs=.5),
sdlog_l_ci = quantile(sdlog, probs=.025),
sdlog_u_ci = quantile(sdlog, probs=.975)
)
SALIDA
meanlog_mean meanlog_l_ci meanlog_u_ci sdlog_mean sdlog_l_ci sdlog_u_ci
1 1.866779 1.724069 2.015255 0.6086726 0.5107204 0.725803R
lognorm_meanlog <- si_fit_lnorm@ests['meanlog',][1]
lognorm_sdlog <- si_fit_lnorm@ests['sdlog',][1]
8.2.4. Ajuste de una distribución Weibull para el intervalo serial
Finalmente, ajuste de una distribución Weibull para los datos del intervalo serial.
R
# Ejecutaremos el modelo durante 4000 iteraciones, descartando las primeras 1000 muestras como burning
n_mcmc_samples <- 3000 # número de muestras a extraer de la posterior (después del burning)
params = list(
dist = "W", # Ajustando una distribución Weibull para el Intervalo Serial (SI)
method = "MCMC", # MCMC usando coarsedatatools
burnin = 1000, # número de muestras de burning (muestras descartadas al comienzo de MCMC)
n1 = 50, # n1 es el número de pares de media y desviación estándar de SI que se extraen
n2 = 50) # n2 es el tamaño de la muestra posterior extraída para cada par de media y desviación estándar de SI
mcmc_control <- make_mcmc_control(
seed = MCMC_seed,
burnin = params$burnin)
dist <- params$dist
config <- make_config(
list(
si_parametric_distr = dist,
mcmc_control = mcmc_control,
seed = overall_seed,
n1 = params$n1,
n2 = params$n2))
# Ajuste el intervalo serial
si_fit_weibull <- coarseDataTools::dic.fit.mcmc(
dat = si_data,
dist = dist,
init.pars = init_mcmc_params(si_data, dist),
burnin = mcmc_control$burnin,
n.samples = n_mcmc_samples,
seed = mcmc_control$seed)
Revise los resultados.
R
# Revise covengencia
converg_diag_weibull <- check_cdt_samples_convergence(si_fit_weibull@samples)
SALIDA
Gelman-Rubin MCMC convergence diagnostic was successful.R
converg_diag_weibull
SALIDA
[1] TRUER
# Guarde las muestra MCMC en un dataframe
si_samples_weibull <- data.frame(
type = 'Symptom onset',
shape = si_fit_weibull@samples$var1,
scale = si_fit_weibull@samples$var2,
p50 = qweibull(
p = 0.5,
shape = si_fit_weibull@samples$var1,
scale = si_fit_weibull@samples$var2)) |>
mutate( # La ecuación para conversión está aquí https://en.wikipedia.org/wiki/Weibull_distribution
mean = scale*gamma(1+1/shape),
sd = sqrt(scale^2*(gamma(1+2/shape)-(gamma(1+1/shape))^2))
)
R
# Obtenga las estadísticas resumen
si_summary_weibull <-
si_samples_weibull %>%
summarise(
mean_mean = quantile(mean,probs=.5),
mean_l_ci = quantile(mean,probs=.025),
mean_u_ci = quantile(mean,probs=.975),
sd_mean = quantile(sd, probs=.5),
sd_l_ci = quantile(sd,probs=.025),
sd_u_ci = quantile(sd,probs=.975)
)
si_summary_weibull
SALIDA
mean_mean mean_l_ci mean_u_ci sd_mean sd_l_ci sd_u_ci
1 7.692701 6.677548 8.809715 4.418743 3.797158 5.456492R
# Obtenga las estadísticas resumen para los parámetros de la distribución.
si_samples_weibull |>
summarise(
shape_mean = quantile(shape, probs=.5),
shape_l_ci = quantile(shape, probs=.025),
shape_u_ci = quantile(shape, probs=.975),
scale_mean = quantile(scale, probs=.5),
scale_l_ci = quantile(scale, probs=.025),
scale_u_ci = quantile(scale, probs=.975)
)
SALIDA
shape_mean shape_l_ci shape_u_ci scale_mean scale_l_ci scale_u_ci
1 1.791214 1.50812 2.090071 8.631295 7.481234 9.943215R
weibull_shape <- si_fit_weibull@ests['shape',][1]
weibull_scale <- si_fit_weibull@ests['scale',][1]
8.2.5. Grafique los resultados para el intervalo serial
Ahora, grafique el ajuste de las tres distribuciones. Asegúrese que la distribución ajuste bien los datos del intervalo serial.
R
ggplot()+
theme_classic()+
geom_bar(data = contacts, aes(x=diff), fill = "#FFAD05") +
scale_y_continuous(limits = c(0,14), breaks = c(0,2,4,6,8,10,12,14), expand = c(0,0)) +
stat_function(
linewidth=.8,
fun = function(z, shape, rate)(dgamma(z, shape, rate) * length(contacts$diff)),
args = list(shape = gamma_shape, rate = gamma_rate),
aes(linetype = 'Gamma')
) +
stat_function(
linewidth=.8,
fun = function(z, meanlog, sdlog)(dlnorm(z, meanlog, sdlog) * length(contacts$diff)),
args = list(meanlog = lognorm_meanlog, sdlog = lognorm_sdlog),
aes(linetype ='Log normal')
) +
stat_function(
linewidth=.8,
fun = function(z, shape, scale)(dweibull(z, shape, scale) * length(contacts$diff)),
args = list(shape = weibull_shape, scale = weibull_scale),
aes(linetype ='Weibull')
) +
scale_linetype_manual(values = c('solid','twodash','dotted')) +
labs(x = "Days", y = "Number of case pairs") +
theme(
legend.position = c(0.75, 0.75),
plot.margin = margin(.2,5.2,.2,.2, "cm"),
legend.title = element_blank(),
)
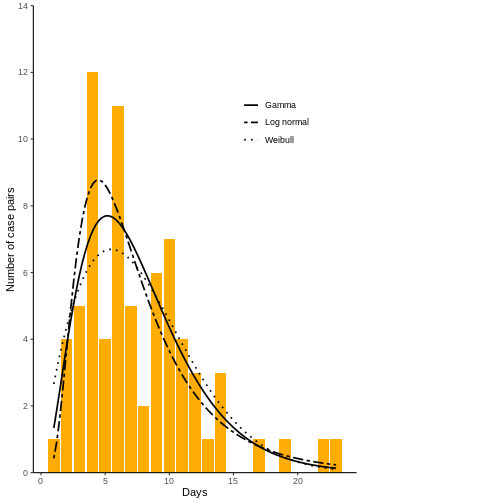
Ahora calcule el WAIC y LOOIC. coarseDataTools no tiene
una forma integrada de hacer esto, por lo que se necesita calcular la
verosimilitud a partir de las cadenas MCMC y utilizar el paquete
loo en R.
R
# Cargue las funciones de verosimilitud de coarseDataTools
calc_looic_waic <- function(symp, symp_si, dist){
# Prepare los datos y parámetros para el paquete loo
# Se necesita: una matriz de tamaño S por N, donde S es el tamaño de la muestra posterior (con todas las cadenas fusionadas)
# y N es el número de puntos de datos
mat <- matrix(NA, nrow = length(symp_si@samples$var1), ncol = nrow(si_data))
for (i in 1:nrow(symp)) {
for (j in 1:length(symp_si@samples$var1)){
L <- diclik2(par1 = symp_si@samples$var1[j],
par2 = symp_si@samples$var2[j],
EL = symp$EL[i], ER = symp$ER[i], SL = symp$SL[i], SR = symp$SR[i],
dist = dist)
mat[j,i] <- L
}
}
return(list(waic = waic(log(mat)),
looic = loo(log(mat)))) # now we have to take the log to get log likelihood
}
compare_gamma <- calc_looic_waic(symp = si_data, symp_si = si_fit_gamma, dist = "G")
compare_lnorm <- calc_looic_waic(symp = si_data, symp_si = si_fit_lnorm, dist = "L")
compare_weibull <- calc_looic_waic(symp = si_data, symp_si = si_fit_weibull, dist = "W")
# Imprima resultados
compare_gamma[["waic"]]$estimates
SALIDA
Estimate SE
elpd_waic -202.009546 7.0118463
p_waic 1.936991 0.4409454
waic 404.019093 14.0236925R
compare_lnorm[["waic"]]$estimates
SALIDA
Estimate SE
elpd_waic -202.215546 7.0178113
p_waic 1.874728 0.4106866
waic 404.431092 14.0356226R
compare_weibull[["waic"]]$estimates
SALIDA
Estimate SE
elpd_waic -203.941362 6.9020056
p_waic 2.083623 0.6633186
waic 407.882723 13.8040112R
compare_gamma[["looic"]]$estimates
SALIDA
Estimate SE
elpd_loo -202.015856 7.0144149
p_loo 1.943301 0.4437589
looic 404.031713 14.0288297R
compare_lnorm[["looic"]]$estimates
SALIDA
Estimate SE
elpd_loo -202.218954 7.0182826
p_loo 1.878136 0.4114664
looic 404.437909 14.0365651R
compare_weibull[["looic"]]$estimates
SALIDA
Estimate SE
elpd_loo -203.956018 6.9097884
p_loo 2.098279 0.6725387
looic 407.912036 13.8195768Incluya lo siguiente cuando reporte el intervalo serial:
Media e intervalo de credibilidad del 95%
Desviación estándar y e intervalo de credibilidad del 95%
Los parámetros de la distribución ajustada (e.g., shape y scale para distribución gamma)
💡 Preguntas (7)
- ¿Qué distribución tiene el menor WAIC y LOOIC??
R
si_summary_gamma
SALIDA
mean_mean mean_l_ci mean_u_ci sd_mean sd_l_ci sd_u_ci
1 7.659641 6.65395 8.707372 4.342087 3.602425 5.481316R
si_summary_lnorm
SALIDA
mean_mean mean_l_ci mean_u_ci sd_mean sd_l_ci sd_u_ci
1 7.780719 6.692829 9.300588 5.189349 3.936678 7.289224R
si_summary_weibull
SALIDA
mean_mean mean_l_ci mean_u_ci sd_mean sd_l_ci sd_u_ci
1 7.692701 6.677548 8.809715 4.418743 3.797158 5.456492_______Pausa 3 _________
9. Medidas de control
9.1 Analicemos el resultado juntos
Ahora ha finalizado el análisis estadístico 🥳
Compare el período de incubación y el intervalo serial.
¿Cuál es más largo?
¿Ocurre la transmisión pre-sintomática con la Enfermedad X?
¿Serán medidas efectivas aislar a los individuos sintomáticos y rastrear y poner en cuarentena a sus contactos?
Si no lo son, ¿qué otras medidas se pueden implementar para frenar el brote?
10. Valores verdaderos
Los valores verdaderos usados para simular las epidemías fueron:
| Distribución | Media (días) | Desviación estándar (días) | |||
| Grupo 1 | Log normal | 5.7 | 4.6 | |
| Grupo 2 | Weibull | 7.1 | 3.7 | |
| Distribución | Media (días) | Desviación estándar (días) | |||
| Group 1 | Gamma | 8.4 | 4.9 | |
| Group 2 | Gamma | 4.8 | 3.3 | |
¿Cómo se comparan sus estimaciones con los valores verdaderos? Discuta las posibles razones para las diferencias.
Puntos Clave
Revise si al final de esta lección adquirió estas competencias:
Comprender los conceptos clave de las distribuciones de retrasos epidemiológicos para la Enfermedad X.
Entender las estructuras de datos y las herramientas para el análisis de datos de rastreo de contactos.
Aprender cómo ajustar las estimaciones del intervalo serial y del período de incubación de la Enfermedad X teniendo en cuenta la censura por intervalo usando un marco de trabajo Bayesiano.
Aprender a utilizar estos parámetros para informar estrategias de control en un brote de un patógeno desconocido.
11. Recursos adicionales
En este práctica, en gran medida se ignoraron los sesgos de
truncamiento a la derecha y sesgo dinámico, en parte debido a la falta
de herramientas fácilmente disponibles que implementen las mejores
prácticas. Para aprender más sobre cómo estos sesgos podrían afectar la
estimación de las distribuciones de retraso epidemiológico en tiempo
real, recomendamos un tutorial sobre el paquete
dynamicaltruncation en R de Sam Abbott y Sang Woo Park (https://github.com/parksw3/epidist-paper).
13. Referencias
- Reich NG et al. Estimating incubation period distributions with coarse data. Stat Med. 2009;28:2769–84. PubMed https://doi.org/10.1002/sim.3659
- Miura F et al. Estimated incubation period for monkeypox cases confirmed in the Netherlands, May 2022. Euro Surveill. 2022;27(24):pii=2200448. https://doi.org/10.2807/1560-7917.ES.2022.27.24.2200448
- Abbott S, Park Sang W. Adjusting for common biases in infectious disease data when estimating distributions. 2022 [cited 7 November 2023]. https://github.com/parksw3/dynamicaltruncation
- Lessler J et al. Incubation periods of acute respiratory viral infections: a systematic review, The Lancet Infectious Diseases. 2009;9(5):291-300. https://doi.org/10.1016/S1473-3099(09)70069-6.
- Cori A et al. Estimate Time Varying Reproduction Numbers from Epidemic Curves. 2022 [cited 7 November 2023]. https://github.com/mrc-ide/EpiEstim
- Lambert B. A Student’s Guide to Bayesian Statistics. Los Angeles, London, New Delhi, Singapore, Washington DC, Melbourne: SAGE, 2018.
- Vehtari A et al. Rank-normalization, folding, and localization: An improved R-hat for assessing convergence of MCMC. Bayesian Analysis 2021: Advance publication 1-28. https://doi.org/10.1214/20-BA1221
- Nishiura H et al. Serial interval of novel coronavirus (COVID-19) infections. Int J Infect Dis. 2020;93:284-286. https://doi.org/10.1016/j.ijid.2020.02.060